

来源:EMNLP2024
在现有的 ABSA 任务中,大多数方法主要利用基于注意力分数的语义或句法信息,这些方法容易受到不相关上下文的干扰,并且往往缺乏特定数据层面的情感知识。此文首次提出了在 Attribution (归因)的角度进行 ABSA 任务的预测。
由于是首次使用,简单的查阅一下归因技术的原理:
Attribution(归因) 是指一种技术,用于量化输入数据(例如文本中的单词或短语)对模型预测的贡献大小。这种归因过程帮助我们理解模型的决策过程,并解释为什么模型会输出特定的结果。
局限性
1. 注意力机制通常受句子内部噪声的影响,并且注意力的预测并不稳定

例如上图中,方面词 “service” 对无关观点词 “pretty” 和 “good” 的注意力分数过高。

再例如上图中,在对方面词 “movie” 进行情感极性预测时,作者对无关词构建了注意力权重,忽略了观点词,但仍然得到了正确的预测
2. 与方面词无关的句法信息可能是冗余的,甚至可能引入噪声。
贡献
针对上面的两点局限性,作者将归因分析引入到 ABSA 任务中,提出了一种动态多粒度属性网络( Dynamic Multi-granularity Attribution Network,DMAN )。
归因(Attribution)信息反映了不同表征对预测的重要性,包含了特定数据层面的情感推理知识。
主要贡献有三点:
- 使用集成梯度 IG (一种成熟的基于梯度的归因方法)来计算 token 的重要性分数。设计了多步属性分析来捕获 token 在理解过程中的动态显著性。利用堆叠的自注意力模块结合 IG 来计算每一层的归因得分,并采用Top – K策略来过滤掉低值的维度。
- 在 token 和 span 两个层次上结合语义表征,得到多粒度的归因得分
- 基于依存树构建邻接矩阵,然后利用得到的归因得分对不同层次的GCN初始化不同的邻接矩阵
模型分析
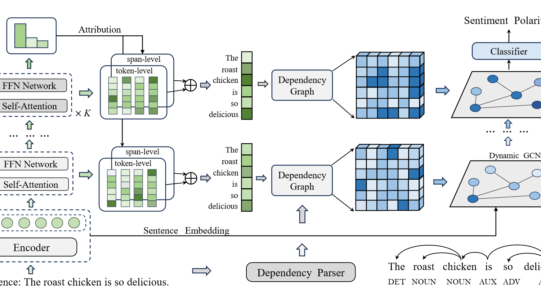
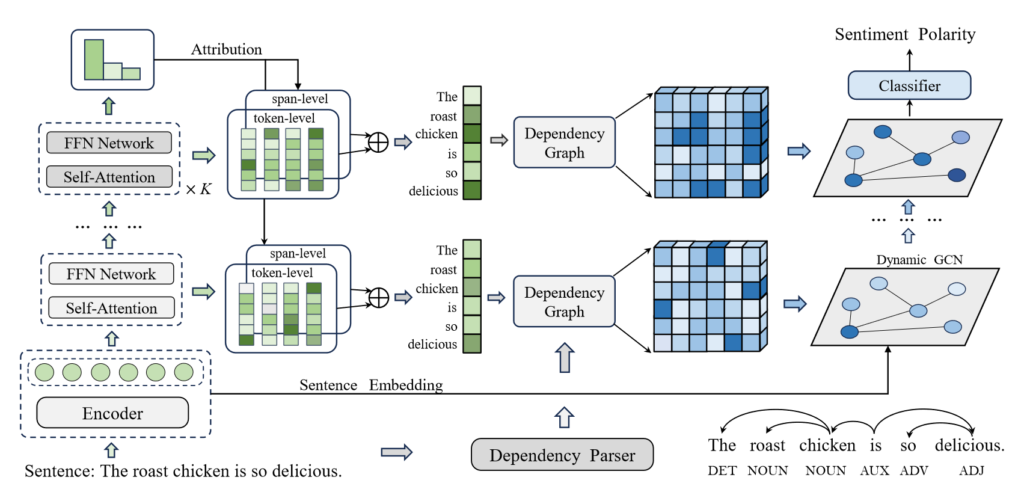
模型图如上,作者采用了 BERT 作为句子编码器来提取特定方面词的上下文表示。
作者提出的动态多粒度属性网络主要包括三个主要部分(模型图从左至右):
- 多步归因提取(Multi-step Attribution Extraction)
- 多粒度归因(Multi-granularity Attribution)
- 动态句法集中(Dynamic Syntax Concentration)
Multi-step Attribution Extraction
Integrated Gradients(集成梯度)
利用 Integrated Gradients (IG) 方法,定义了 IG 的计算公式,通过在输入空间的路径上累积梯度来重要性分数。
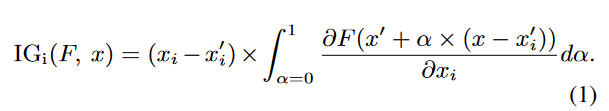
其中 x′ 是基准特征,文中使用零向量作为基准特征,α 是插值参数。
Attribution Extraction(归因提取)
构建多层堆叠的自注意力(Self-Attention)和前馈网络模块,用来动态捕捉语义变化。特征向量的每一层输出会被用于计算归因。初始输入是 BERT 输出的句子嵌入。
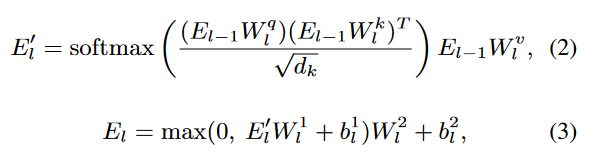
随后,作者将栈式架构的最终输出映射为一个概率分布Pc ( c 是表示情感极性的标签),在作者的方法中,我们将函数 E→Pc 表示为 Fc,并对输入特征的每个维度进行详尽的属性分析,得到 i 个 token 的归因得分,记为 IGi
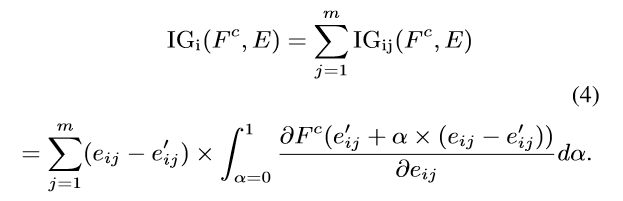
在这个过程中,作者实际上使用了一种有效的近似技术来估计积分计算,从而显著提高了计算效率。近似方法可以表述为离散求和:
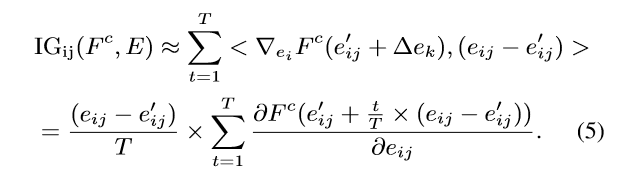
在作者的方法中,没有考虑正负符号,以避免在对各维度的归因分数求和时出现相互抵消的情况。更具体地,作者使用绝对值来聚合每个维度上的归因,从而得到 token 级别的归因值。
直观来说,并不是所有维度都具有相同的重要性,某些维度始终保持较低的值,未能有效区分不同的表征或归因阶段,所以作者使用了 TOP-K 算法来筛选所需要的维度:
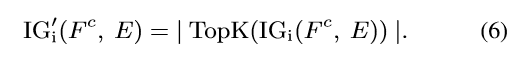
在作者的方法中,对每个自注意力块进行归因分析,以彻底阐明动态语义理解。第k层的归因值记为Vk(其中∥表示级联运算,Vk∈{ vk_1,vk_2,..,vk_n):
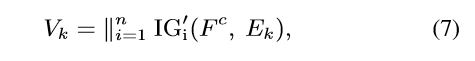
Multi-granularity Attribution
传统的 ABSA 方法多关注单一粒度(如 token),忽略了文本的多层次结构(如词组、短语)。这里作者采用了 token 和 span 两个粒度,获得更全面的语义表示,提升对情感表达的理解。
Token-level:为每个 token 分配归因分数。
Span-level:利用工具(如 spaCy)构建语义上连续的短语(span),对短语中的所有 token 的归因分数取平均,得到短语级别的归因值。
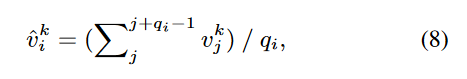
将 token 和 span 级别归因融合,平衡两种粒度的重要性:
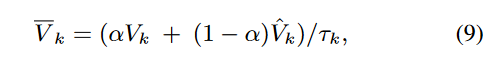
Dynamic Syntax Concentration
句法信息对 ABSA 任务尤为重要,但其相关性是动态变化的,不同阶段可能需要关注不同的句法关系。
构建依存关系图的邻接矩阵 A ,表示 token 间的依存关系:
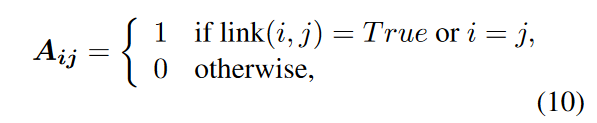
使用多步归因分数 Vk 调整邻接矩阵,得到动态邻接矩阵 Ak,反映不同阶段的语法重要性。然后,利用 GCN 来捕捉句法知识。
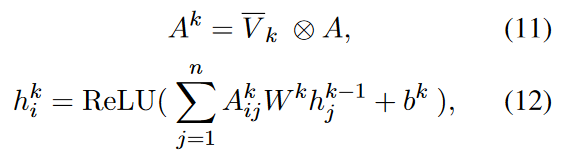
模型训练
归因分析
为确保堆叠式自我关注架构能提供有效的归因知识,作者首先对归因模块进行了微调。具体来说,将最终表示映射为概率分布 P,并应用以下函数来训练归因模块:
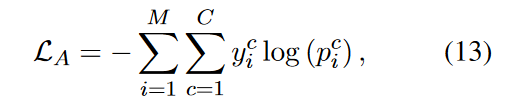
其中,yc i 是地面真实标签,C 是标签数,M 是训练样本数。
情感分类
得到动态语法增强表示 H 后,将其与句子语义表示 Ek 连接,得到最终的情感分类特征。然后,我们通过 softmax 将其映射为情感极性的概率:
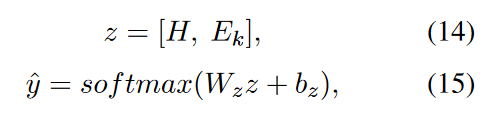
最后,我们使用交叉熵损失作为目标函数:
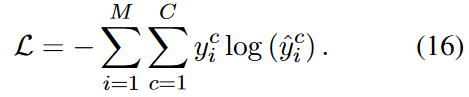
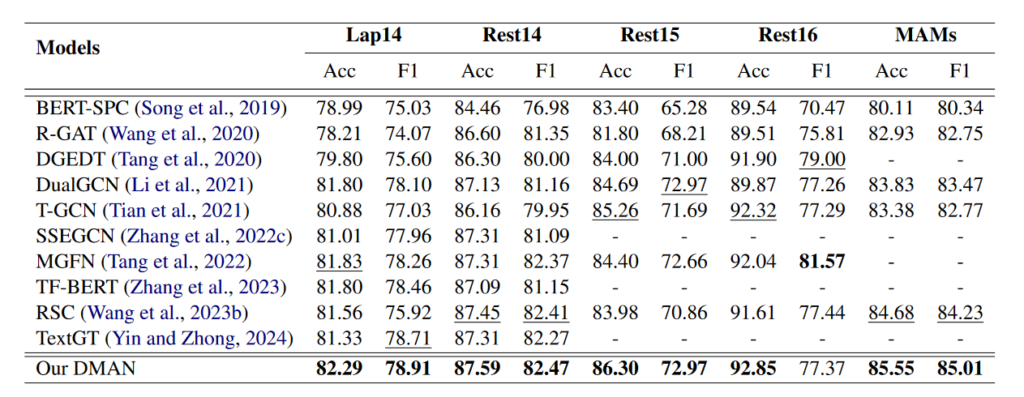
实验结果
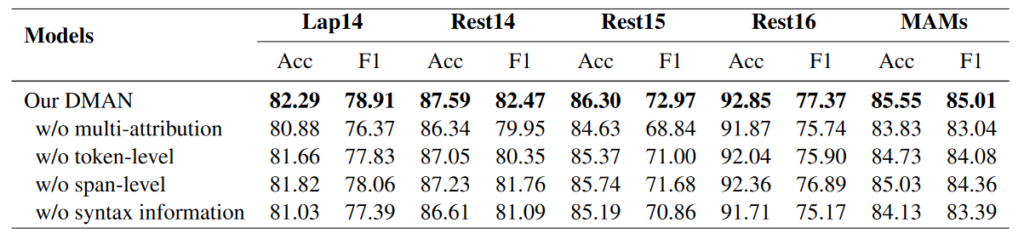
消融实验:
总结
个人认为这篇文章最大的贡献是首次引入了 Attribution ,且达到了不错的效果。
通过归因分数,可以直观理解哪些单词或短语对模型的情感预测起到了关键作用。并且在细粒度情感分析中,归因分数可以帮助识别哪些词或短语与目标属性相关。
在文章中,归因被用来:
- 动态调整依存关系图的权重,突出重要的句法关系。
- 在 Token-level 和 Span-level 上聚合特征贡献,捕捉多粒度信息。