

行为型模式重点关注 类与类之间的交互与协作。如同在工作中,每个人的行为都可能影响到其他同事,同时每个人也会受到别人的影响。我们一边接收上级的指令,一边派发任务给下级,在这样的协作中完成一项项伟大的工作。程序在运行时,每个对象都不是孤立的,他们可以通过通信与协作完成种种复杂的功能。
行为型模式共 11 种,分别是:
- 责任链模式
- 命令模式
- 解释器模式
- 迭代器模式
- 中介者模式
- 备忘录模式
- 观察者模式
- 状态模式
- 策略模式
- 模板方法模式
- 访问者模式
责任链模式
我们每个人在工作中都承担着一定的责任,比如程序员承担着开发新功能、修改 bug 的责任,运营人员承担着宣传的责任、HR 承担着招聘新人的责任。我们每个人的责任与这个责任链有什么关系吗?
——答案是并没有太大关系。
(小朋友你是否有很多问号???)
也不是完全没有关系,主要是因为每个人在不同岗位上的责任是分散的,分散的责任组合在一起更像是一张网,无法组成一条链。
同一个岗位上的责任,就可以组成一条链。举个切身的例子,比如:普通的程序员可以解决中等难度的 bug,优秀程序员可以解决困难的 bug,而菜鸟程序员只能解决简单的 bug。为了将其量化,我们用一个数字来表示 bug 的难度,(0, 20] 表示简单,(20,50] 表示中等, (50,100] 表示困难,我们来模拟一个 bug 解决的流程。
“解决 bug” 程序 1.0
新建一个 bug 类:
public class Bug {
// bug 的难度值
int value;
public Bug(int value) {
this.value = value;
}
}新建一个程序员类:
public class Programmer {
// 程序员类型:菜鸟、普通、优秀
public String type;
public Programmer(String type) {
this.type = type;
}
public void solve(Bug bug) {
System.out.println(type + "程序员解决了一个难度为 " + bug.value + " 的 bug");
}
}客户端:
public class Client {
@Test
public void test() {
Programmer newbie = new Programmer("菜鸟");
Programmer normal = new Programmer("普通");
Programmer good = new Programmer("优秀");
Bug easy = new Bug(20);
Bug middle = new Bug(50);
Bug hard = new Bug(100);
// 依次尝试解决 bug
handleBug(newbie, easy);
handleBug(normal, easy);
handleBug(good, easy);
handleBug(newbie, middle);
handleBug(normal, middle);
handleBug(good, middle);
handleBug(newbie, hard);
handleBug(normal, hard);
handleBug(good, hard);
}
public void handleBug(Programmer programmer, Bug bug) {
if (programmer.type.equals("菜鸟") && bug.value > 0 && bug.value <= 20) {
programmer.solve(bug);
} else if (programmer.type.equals("普通") && bug.value > 20 && bug.value <= 50) {
programmer.solve(bug);
} else if (programmer.type.equals("优秀") && bug.value > 50 && bug.value <= 100) {
programmer.solve(bug);
}
}
}运行程序,输出如下:
菜鸟程序员解决了一个难度为 20 的 bug
普通程序员解决了一个难度为 50 的 bug
优秀程序员解决了一个难度为 100 的 bug功能完美实现了,但在这个程序中,我们让每个程序员都尝试处理了每一个 bug,相当于大家围着讨论每个 bug 该由谁解决,这无疑是非常低效的做法。那么我们要怎么才能优化呢?
“解决 bug” 程序 2.0
实际上,许多公司会选择让项目经理来分派任务,项目经理会根据 bug 的难度指派给不同的人解决。
引入 ProjectManager 类:
public class ProjectManager {
Programmer newbie = new Programmer("菜鸟");
Programmer normal = new Programmer("普通");
Programmer good = new Programmer("优秀");
public void assignBug(Bug bug) {
if (bug.value > 0 && bug.value <= 20) {
System.out.println("项目经理将这个简单的 bug 分配给了菜鸟程序员");
newbie.solve(bug);
} else if (bug.value > 20 && bug.value <= 50) {
System.out.println("项目经理将这个中等的 bug 分配给了普通程序员");
normal.solve(bug);
} else if (bug.value > 50 && bug.value <= 100) {
System.out.println("项目经理将这个困难的 bug 分配给了优秀程序员");
good.solve(bug);
}
}
}我们让项目经理管理所有的程序员,并且根据 bug 的难度指派任务。这样一来,所有的 bug 只需传给项目经理分配即可,修改客户端如下:
public class Client2 {
@Test
public void test() {
ProjectManager manager = new ProjectManager();
Bug easy = new Bug(20);
Bug middle = new Bug(50);
Bug hard = new Bug(100);
manager.assignBug(easy);
manager.assignBug(middle);
manager.assignBug(hard);
}
}运行程序,输出如下:
项目经理将这个简单的 bug 分配给了菜鸟程序员
菜鸟程序员解决了一个难度为 20 的 bug
项目经理将这个中等的 bug 分配给了普通程序员
普通程序员解决了一个难度为 50 的 bug
项目经理将这个困难的 bug 分配给了优秀程序员
优秀程序员解决了一个难度为 100 的 bug看起来很美好,除了项目经理在骂骂咧咧地反驳这个方案。
在这个经过修改的程序中,项目经理一个人承担了分配所有 bug 这个体力活。程序没有变得简洁,只是把复杂的逻辑从客户端转移到了项目经理类中。
而且项目经理类承担了过多的职责,如果以后新增一类程序员,必须改动项目经理类,将其处理 bug 的职责插入分支判断语句中。
所以,我们需要更优的解决方案,那就是——责任链模式
“解决 bug” 程序 3.0
责任链模式:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
在本例的场景中,每个程序员的责任都是“解决这个 bug”,当测试提出一个 bug 时,可以走这样一条责任链:
- 先交由菜鸟程序员之手,如果是简单的 bug,菜鸟程序员自己处理掉。如果这个 bug 对于菜鸟程序员来说太难了,交给普通程序员
- 如果是中等难度的 bug,普通程序员处理掉。如果他也解决不了,交给优秀程序员
- 优秀程序员处理掉困难的 bug
有的读者会提出疑问,如果优秀程序员也无法处理这个 bug 呢?
——那当然是处理掉这个假冒优秀程序员。
修改客户端如下:
public class Client3 {
@Test
public void test() throws Exception {
Programmer newbie = new Programmer("菜鸟");
Programmer normal = new Programmer("普通");
Programmer good = new Programmer("优秀");
Bug easy = new Bug(20);
Bug middle = new Bug(50);
Bug hard = new Bug(100);
// 链式传递责任
if (!handleBug(newbie, easy)) {
if (!handleBug(normal, easy)) {
if (!handleBug(good, easy)) {
throw new Exception("Kill the fake good programmer!");
}
}
}
if (!handleBug(newbie, middle)) {
if (!handleBug(normal, middle)) {
if (!handleBug(good, middle)) {
throw new Exception("Kill the fake good programmer!");
}
}
}
if (!handleBug(newbie, hard)) {
if (!handleBug(normal, hard)) {
if (!handleBug(good, hard)) {
throw new Exception("Kill the fake good programmer!");
}
}
}
}
public boolean handleBug(Programmer programmer, Bug bug) {
if (programmer.type.equals("菜鸟") && bug.value > 0 && bug.value <= 20) {
programmer.solve(bug);
return true;
} else if (programmer.type.equals("普通") && bug.value > 20 && bug.value <= 50) {
programmer.solve(bug);
return true;
} else if (programmer.type.equals("优秀") && bug.value > 50 && bug.value <= 100) {
programmer.solve(bug);
return true;
}
return false;
}
}首先我们将 handleBug 方法的签名改为了返回一个 boolean 值,如果此 bug 被处理了,返回 true;否则返回 false,使得责任沿着菜鸟-> 普通 -> 优秀这条链继续传递。
运行程序,输出如下:
菜鸟程序员解决了一个难度为 20 的 bug
普通程序员解决了一个难度为 50 的 bug
优秀程序员解决了一个难度为 100 的 bug熟悉责任链模式的同学应该可以看出,这个责任链模式和我们平时使用的不太一样。事实上,这段代码已经很好地体现了责任链模式的基本思想。我们平时使用的责任链模式只是在面向对象的基础上,将这段代码封装了一下,如 4.0 所示。
“解决 bug” 程序 4.0
新建一个程序员抽象类:
public abstract class Programmer {
protected Programmer next;
public void setNext(Programmer next) {
this.next = next;
}
abstract void handle(Bug bug);
}在这个抽象类中:
- next 对象表示如果自己解决不了,需要将责任传递给的下一个人;
- handle 方法表示自己处理此 bug 的逻辑,在这里判断是自己解决或者继续传递。
新建菜鸟程序员类:
public class NewbieProgrammer extends Programmer {
@Override
public void handle(Bug bug) {
if (bug.value > 0 && bug.value <= 20) {
solve(bug);
} else if (next != null) {
next.handle(bug);
}
}
private void solve(Bug bug) {
System.out.println("菜鸟程序员解决了一个难度为 " + bug.value + " 的 bug");
}
}新建菜鸟程序员类:
public class NewbieProgrammer extends Programmer {
@Override
public void handle(Bug bug) {
if (bug.value > 0 && bug.value <= 20) {
solve(bug);
} else if (next != null) {
next.handle(bug);
}
}
private void solve(Bug bug) {
System.out.println("菜鸟程序员解决了一个难度为 " + bug.value + " 的 bug");
}
}新建普通程序员类:
public class NormalProgrammer extends Programmer {
@Override
public void handle(Bug bug) {
if (bug.value > 20 && bug.value <= 50) {
solve(bug);
} else if (next != null) {
next.handle(bug);
}
}
private void solve(Bug bug) {
System.out.println("普通程序员解决了一个难度为 " + bug.value + " 的 bug");
}
}新建优秀程序员类:
public class GoodProgrammer extends Programmer {
@Override
public void handle(Bug bug) {
if (bug.value > 50 && bug.value <= 100) {
solve(bug);
} else if (next != null) {
next.handle(bug);
}
}
private void solve(Bug bug) {
System.out.println("优秀程序员解决了一个难度为 " + bug.value + " 的 bug");
}
}客户端测试:
public class Client4 {
@Test
public void test() {
NewbieProgrammer newbie = new NewbieProgrammer();
NormalProgrammer normal = new NormalProgrammer();
GoodProgrammer good = new GoodProgrammer();
Bug easy = new Bug(20);
Bug middle = new Bug(50);
Bug hard = new Bug(100);
// 组成责任链
newbie.setNext(normal);
normal.setNext(good);
// 从菜鸟程序员开始,沿着责任链传递
newbie.handle(easy);
newbie.handle(middle);
newbie.handle(hard);
}
}在客户端中,我们通过 setNext() 方法将三个程序员组成了一条责任链,由菜鸟程序员接收所有的 bug,发现自己不能处理的 bug,就传递给普通程序员,普通程序员收到 bug 后,如果发现自己不能解决,则传递给优秀程序员。
责任链思想在生活中有很多应用,比如假期审批、加薪申请等,在员工提出申请后,从经理开始,由你的经理决定自己处理或是交由更上一层的经理处理。
再比如处理客户投诉时,从基层的客服人员开始,决定自己回应或是上报给领导,领导再判断是否继续上报。
假期审批
public class LeaveRequest {
private String name;
private int leaveDays;
private String reason;
public LeaveRequest(String name, int leaveDays, String reason) {
this.name = name;
this.leaveDays = leaveDays;
this.reason = reason;
}
public LeaveRequest() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getLeaveDays() {
return leaveDays;
}
public void setLeaveDays(int leaveDays) {
this.leaveDays = leaveDays;
}
public String getReason() {
return reason;
}
public void setReason(String reason) {
this.reason = reason;
}
}
//抽象类 领导者
abstract class Leader {
protected String name;
public Leader(String name) {
this.name = name;
}
//责任后继对象
protected Leader nextLeader;
public void setNextLeader(Leader nextLeader){
this.nextLeader=nextLeader;
}
//处理请求的方法,传入请求
public abstract void handleRequest(LeaveRequest request);
}
class Director extends Leader{
public Director(String name) {
super(name);
}
@Override
public void handleRequest(LeaveRequest request) {
if(request.getLeaveDays()<3){
System.out.println(request.getName()+"请假"+request.getLeaveDays()+"天,"+name+"审批通过");
}else{
if(this.nextLeader!=null){
this.nextLeader.handleRequest(request);
}
}
}
}
class Manager extends Leader{
public Manager(String name) {
super(name);
}
@Override
public void handleRequest(LeaveRequest request) {
if(request.getLeaveDays()>=3&&request.getLeaveDays()<10){
System.out.println(request.getName()+"请假"+request.getLeaveDays()+"天,"+name+"审批通过");
}else{
if(this.nextLeader!=null){
this.nextLeader.handleRequest(request);
}
}
}
}
class GeneralManager extends Leader{
public GeneralManager(String name) {
super(name);
}
@Override
public void handleRequest(LeaveRequest request) {
if(request.getLeaveDays()>=10){
System.out.println(request.getName()+"请假"+request.getLeaveDays()+"天,"+name+"审批通过");
}
}
}
class chainOfResponsibility{ //测试类
public static void main(String[] args) {
LeaveRequest request = new LeaveRequest();
request.setName("张三");
request.setReason("结婚");
request.setLeaveDays(10);
Director director = new Director("组长");
Manager manager = new Manager("项目经理");
GeneralManager generalManager = new GeneralManager("总经理");
director.setNextLeader(manager);
manager.setNextLeader(generalManager);
director.handleRequest(request);
}
}张三请假10天,总经理审批通过通过这个例子,我们已经了解到,责任链主要用于处理职责相同,程度不同的类。
其主要优点有:
- 降低了对象之间的耦合度。在责任链模式中,客户只需要将请求发送到责任链上即可,无须关心请求的处理细节和请求的传递过程,所以责任链将请求的发送者和请求的处理者解耦了。
- 扩展性强,满足开闭原则。可以根据需要增加新的请求处理类。
- 灵活性强。可以动态地改变链内的成员或者改变链的次序来适应流程的变化。
- 简化了对象之间的连接。每个对象只需保持一个指向其后继者的引用,不需保持其他所有处理者的引用,这避免了使用众多的条件判断语句。
- 责任分担。每个类只需要处理自己该处理的工作,不该处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。不再需要 “项目经理” 来处理所有的责任分配任务。
但我们在使用中也发现了它的一个明显缺点,如果这个 bug 没人处理,可能导致 “程序员祭天” 异常。其主要缺点有:
- 不能保证每个请求一定被处理,该请求可能一直传到链的末端都得不到处理。
- 如果责任链过长,请求的处理可能涉及多个处理对象,系统性能将受到一定影响。
- 责任链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于责任链拼接次序错误而导致系统出错,比如可能出现循环调用。
命令模式
近年来,智能家居越来越流行。躺在家中,只需要打开对应的 app,就可以随手控制家电开关。但随之而来一个问题,手机里的 app 实在是太多了,每一个家具公司都想要提供一个 app 给用户,以求增加用户粘性,推广他们的其他产品等。
站在用户的角度来看,有时我们只想打开一下电灯,却要先看到恼人的 “新式电灯上新” 的弹窗通知,让人烦不胜烦。如果能有一个万能遥控器将所有的智能家居开关综合起来,统一控制,一定会方便许多。
说干就干,笔者立马打开 PS,设计了一张草图:
我们先来看下四个智能家居类的结构,大门类:
public class Door {
public void openDoor() {
System.out.println("门打开了");
}
public void closeDoor() {
System.out.println("门关闭了");
}
}电灯类:
public class Light {
public void lightOn() {
System.out.println("打开了电灯");
}
public void lightOff() {
System.out.println("关闭了电灯");
}
}电视类:
public class Tv {
public void TurnOnTv() {
System.out.println("电视打开了");
}
public void TurnOffTv() {
System.out.println("电视关闭了");
}
}音乐类:
public class Music {
public void play() {
System.out.println("开始播放音乐");
}
public void stop() {
System.out.println("停止播放音乐");
}
}由于是不同公司的产品,所以接口有所不同,接下来就一起来实现我们的万能遥控器!
万能遥控器1.0
// 初始化开关
Switch switchDoor = 省略绑定UI代码;
Switch switchLight = 省略绑定UI代码;
Switch switchTv = 省略绑定UI代码;
Switch switchMusic = 省略绑定UI代码;
// 初始化智能家居
Door door = new Door();
Light light = new Light();
Tv tv = new Tv();
Music music = new Music();
// 大门开关遥控
switchDoor.setOnCheckedChangeListener((view, isChecked) -> {
if (isChecked) {
door.openDoor();
} else {
door.closeDoor();
}
});
// 电灯开关遥控
switchLight.setOnCheckedChangeListener((view, isChecked) -> {
if (isChecked) {
light.lightOn();
} else {
light.lightOff();
}
});
// 电视开关遥控
switchTv.setOnCheckedChangeListener((view, isChecked) -> {
if (isChecked) {
tv.TurnOnTv();
} else {
tv.TurnOffTv();
}
});
// 音乐开关遥控
switchMusic.setOnCheckedChangeListener((view, isChecked) -> {
if (isChecked) {
music.play();
} else {
music.stop();
}
});这份代码很直观,在每个开关状态改变时,调用对应家居的 API 实现打开或关闭。
只有这样的功能实在是太单一了,接下来我们再为它添加一个有趣的功能。
万能遥控器2.0
一般来说,电视遥控器上都有一个回退按钮,用来回到上一个频道。相当于文本编辑器中的 “撤销” 功能,既然别的小朋友都有,那我们也要!

UI 设计倒是简单,底部添加一个按钮即可。代码设计就比较复杂了,我们需要保存上一步操作,并且将其回退。
初步的想法是设计一个枚举类 Operation,代表每一步的操作:
public enum Operation {
DOOR_OPEN,
DOOR_CLOSE,
LIGHT_ON,
LIGHT_OFF,
TV_TURN_ON,
TV_TURN_OFF,
MUSIC_PLAY,
MUSIC_STOP
}然后在客户端定义一个 Operation 变量 lastOperation,在每一步操作后,更新此变量。然后在撤销按钮的点击事件中,根据上一步的操作实现回退:
public class Client {
// 上一步的操作
Operation lastOperation;
@Test
protected void test() {
// 初始化开关和撤销按钮
Switch switchDoor = 省略绑定UI代码;
Switch switchLight = 省略绑定UI代码;
Switch switchTv = 省略绑定UI代码;
Switch switchMusic = 省略绑定UI代码;
Button btnUndo = 省略绑定UI代码;
// 初始化智能家居
Door door = new Door();
Light light = new Light();
Tv tv = new Tv();
Music music = new Music();
// 大门开关遥控
switchDoor.setOnCheckedChangeListener((view, isChecked) -> {
if (isChecked) {
lastOperation = Operation.DOOR_OPEN;
door.openDoor();
} else {
lastOperation = Operation.DOOR_CLOSE;
door.closeDoor();
}
});
// 电灯开关遥控
switchLight.setOnCheckedChangeListener((view, isChecked) -> {
if (isChecked) {
lastOperation = Operation.LIGHT_ON;
light.lightOn();
} else {
lastOperation = Operation.LIGHT_OFF;
light.lightOff();
}
});
... 电视、音乐类似
btnUndo.setOnClickListener(view -> {
if (lastOperation == null) return;
// 撤销上一步
switch (lastOperation) {
case DOOR_OPEN:
door.closeDoor();
break;
case DOOR_CLOSE:
door.openDoor();
break;
case LIGHT_ON:
light.lightOff();
break;
case LIGHT_OFF:
light.lightOn();
break;
... 电视、音乐类似
}
});
}
}大功告成,不过这份代码只实现了撤销一步,如果我们需要实现撤销多步怎么做呢?
思考一下,每次回退时,都是先将最后一步 Operation 撤销。对于这种后进先出的结构,我们自然就会想到栈结构,代码如下:
public class Client {
// 所有的操作
Stack<Operation> operations = new Stack<>();
@Test
protected void test() {
// 初始化开关和撤销按钮
Switch switchDoor = 省略绑定UI代码;
Switch switchLight = 省略绑定UI代码;
Switch switchTv = 省略绑定UI代码;
Switch switchMusic = 省略绑定UI代码;
Button btnUndo = 省略绑定UI代码;
// 初始化智能家居
Door door = new Door();
Light light = new Light();
Tv tv = new Tv();
Music music = new Music();
// 大门开关遥控
switchDoor.setOnCheckedChangeListener((view, isChecked) -> {
if (isChecked) {
operations.push(Operation.DOOR_OPEN);
door.openDoor();
} else {
operations.push(Operation.DOOR_CLOSE);
door.closeDoor();
}
});
// 电灯开关遥控
switchLight.setOnCheckedChangeListener((view, isChecked) -> {
if (isChecked) {
operations.push(Operation.LIGHT_ON);
light.lightOn();
} else {
operations.push(Operation.LIGHT_OFF);
light.lightOff();
}
});
...电视、音乐类似
// 撤销按钮
btnUndo.setOnClickListener(view -> {
if (operations.isEmpty()) return;
// 弹出栈顶的上一步操作
Operation lastOperation = operations.pop();
// 撤销上一步
switch (lastOperation) {
case DOOR_OPEN:
door.closeDoor();
break;
case DOOR_CLOSE:
door.openDoor();
break;
case LIGHT_ON:
light.lightOff();
break;
case LIGHT_OFF:
light.lightOn();
break;
...电视、音乐类似
}
});
}
}我们将每一步 Operation 记录到栈中,每次撤销时,弹出栈顶的 Operation,再使用 switch 语句判断,将其恢复。
虽然实现了功能,但代码明显已经变得越来越臃肿了。遥控器知道了太多的细节,它必须要知道每个家居的调用方式。以后有开关加入时,不仅要修改 Status 类,增加新的 Operation,还要修改客户端,增加新的分支判断,导致这个类变成一个庞大的类。不仅违背了单一权责原则,还违背了开闭原则。
万能遥控器3.0
我们期待能有一种设计,让遥控器不需要知道家居的接口。遥控器只需要负责监听用户按下开关,再根据开关状态发出正确的命令,对应的家居在收到命令后做出响应。就可以达到将 “行为请求者” 和 ”行为实现者“ 解耦的目的。
先定义一个命令接口:
public interface ICommand {
void execute();
}接口中只有一个 execute 方法,表示 “执行” 命令。
定义开门命令,实现此接口:
public class DoorOpenCommand implements ICommand {
private Door door;
public void setDoor(Door door) {
this.door = door;
}
@Override
public void execute() {
door.openDoor();
}
}关门命令:
public class DoorCloseCommand implements ICommand {
private Door door;
public void setDoor(Door door) {
this.door = door;
}
@Override
public void execute() {
door.closeDoor();
}
}开灯命令:
public class LightOnCommand implements ICommand {
Light light;
public void setLight(Light light) {
this.light = light;
}
@Override
public void execute() {
light.lightOn();
}
}关灯命令:
public class LightOffCommand implements ICommand {
Light light;
public void setLight(Light light) {
this.light = light;
}
@Override
public void execute() {
light.lightOff();
}
}电视、音乐的命令类似。
可以看到,我们将家居控制的代码转移到了命令类中,当命令执行时,调用对应家具的 API 实现开启或关闭。
客户端代码:
/ 初始化命令
DoorOpenCommand doorOpenCommand = new DoorOpenCommand();
DoorCloseCommand doorCloseCommand = new DoorCloseCommand();
doorOpenCommand.setDoor(door);
doorCloseCommand.setDoor(door);
LightOnCommand lightOnCommand = new LightOnCommand();
LightOffCommand lightOffCommand = new LightOffCommand();
lightOnCommand.setLight(light);
lightOffCommand.setLight(light);
...电视、音乐类似
// 大门开关遥控
switchDoor.setOnCheckedChangeListener((view, isChecked) -> {
if (isChecked) {
doorOpenCommand.execute();
} else {
doorCloseCommand.execute();
}
});
// 电灯开关遥控
switchLight.setOnCheckedChangeListener((view, isChecked) -> {
if (isChecked) {
lightOnCommand.execute();
} else {
lightOffCommand.execute();
}
});
...电视、音乐类似现在,遥控器只知道用户控制开关后,需要执行对应的命令,遥控器并不知道这个命令会执行什么内容,达到了隐藏技术细节的目的。
与此同时,我们还获得了一个附带的好处。由于每个命令都被抽象成了同一个接口,我们可以将开关代码统一起来。客户端优化如下:
public class Client {
@Test
protected void test() {
...初始化
// 大门开关遥控
switchDoor.setOnCheckedChangeListener((view, isChecked) -> {
handleCommand(isChecked, doorOpenCommand, doorCloseCommand);
});
// 电灯开关遥控
switchLight.setOnCheckedChangeListener((view, isChecked) -> {
handleCommand(isChecked, lightOnCommand, lightOffCommand);
});
// 电视开关遥控
switchTv.setOnCheckedChangeListener((view, isChecked) -> {
handleCommand(isChecked, turnOnTvCommand, turnOffTvCommand);
});
// 音乐开关遥控
switchMusic.setOnCheckedChangeListener((view, isChecked) -> {
handleCommand(isChecked, musicPlayCommand, musicStopCommand);
});
}
private void handleCommand(boolean isChecked, ICommand openCommand, ICommand closeCommand) {
if (isChecked) {
openCommand.execute();
} else {
closeCommand.execute();
}
}
}不知不觉中,我们就写出了命令模式的代码。来看下命令模式的定义:
命令模式:将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化,对请求排队或记录请求日志,以及支持可撤销的操作。
使用命令模式后,要实现撤销功能非常容易。
首先,在命令接口中,新增 undo 方法:
public interface ICommand {
void execute();
void undo();
}开门命令中新增 undo:
public class DoorOpenCommand implements ICommand {
private Door door;
public void setDoor(Door door) {
this.door = door;
}
@Override
public void execute() {
door.openDoor();
}
@Override
public void undo() {
door.closeDoor();
}
}关门命令中新增 undo:
public class DoorCloseCommand implements ICommand {
private Door door;
public void setDoor(Door door) {
this.door = door;
}
@Override
public void execute() {
door.closeDoor();
}
@Override
public void undo() {
door.openDoor();
}
}电灯、电视、音乐命令类似。
客户端:
public class Client {
// 所有的命令
Stack<ICommand> commands = new Stack<>();
@Test
protected void test() {
...初始化
// 大门开关遥控
switchDoor.setOnCheckedChangeListener((view, isChecked) -> {
handleCommand(isChecked, doorOpenCommand, doorCloseCommand);
});
// 电灯开关遥控
switchLight.setOnCheckedChangeListener((view, isChecked) -> {
handleCommand(isChecked, lightOnCommand, lightOffCommand);
});
// 电视开关遥控
switchTv.setOnCheckedChangeListener((view, isChecked) -> {
handleCommand(isChecked, turnOnTvCommand, turnOffTvCommand);
});
// 音乐开关遥控
switchMusic.setOnCheckedChangeListener((view, isChecked) -> {
handleCommand(isChecked, musicPlayCommand, musicStopCommand);
});
// 撤销按钮
btnUndo.setOnClickListener(view -> {
if (commands.isEmpty()) return;
// 撤销上一个命令
ICommand lastCommand = commands.pop();
lastCommand.undo();
});
}
private void handleCommand(boolean isChecked, ICommand openCommand, ICommand closeCommand) {
if (isChecked) {
commands.push(openCommand);
openCommand.execute();
} else {
commands.push(closeCommand);
closeCommand.execute();
}
}
}我们同样使用了一个栈结构,用于存储所有的命令,在每次执行命令前,将命令压入栈中。撤销时,弹出栈顶的命令,执行其 undo 方法即可。
命令模式使得客户端的职责更加简洁、清晰了,命令执行、撤销的代码都被隐藏到了命令类中。唯一的缺点是多了很多的命令类,因为我们必须针对每一个命令都设计一个命令类,容易导致类爆炸。
前文的定义中讲到,命令模式还可以用于请求排队。要实现请求排队功能,只需创建一个命令队列,将每个需要执行的命令依次传入队列中,然后工作线程不断地从命令队列取出队列头的命令执行即可。
事实上,安卓 app 的界面就是这么实现的。源码中使用了一个阻塞式死循环 Looper,不断地从 MessageQueue 中取出消息,交给 Handler 处理,用户的每一个操作也会通过 Handler 传递到 MessageQueue 中排队执行。
命令模式可以说将封装发挥得淋漓尽致。在我们平时的程序设计中,最常用的封装是将拥有一类职责的对象封装成类,而命令对象的唯一职责就是通过 execute 去调用一个方法,也就是说它将 “方法调用” 这个步骤封装起来了,使得我们可以对 “方法调用” 进行排队、撤销等处理。
命令模式的主要优点如下:
- 降低系统的耦合度。将 “行为请求者” 和 ”行为实现者“ 解耦。
- 扩展性强。增加或删除命令非常方便,并且不会影响其他类。
- 封装 “方法调用”,方便实现 Undo 和 Redo 操作。
- 灵活性强,可以实现宏命令。
它的主要缺点是:
- 会产生大量命令类。增加了系统的复杂性。
解释器模式
我国 IT 界历来有一个汉语编程梦,虽然各方对于汉语编程争论不休,甚至上升到民族大义的高度,本文不讨论其对与错,但我们不妨来尝试一下,定义一个简单的中文编程语法。
在设计模式中,解释器模式就是用来自定义语法的,它的定义如下。
解释器模式(Interpreter Pattern):给定一门语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。
解释器模式较为晦涩难懂,但本文我们仍然深入浅出,通过一个简单的例子来学习解释器模式:使用中文编写出十以内的加减法公式。比如:
- 输入“一加一”,输出结果 2
- 输入“一加一加一”,输出结果 3
- 输入“二加五减三”,输出结果 4
- 输入“七减五加四减一”,输出结果 5
- 输入“九减五加三减一”,输出结果 6
看到这个需求,我们很容易想到一种写法:将输入的字符串分割成单个字符,把数字字符通过switch-case转换为数字,再通过计算符判断是加法还是减法,对应做加、减计算,最后返回结果即可。
计划的确可行,但这实在太面向过程了,众所周知面向过程编程会有耦合度高,不易扩展等缺点。接下来我们尝试按照面向对象的写法来实现这个功能。
按照面向对象的编程思想,我们应该为公式中不同种类的元素建立一个对应的对象。那么我们先分析一下公式中的成员:
- 数字:
零到九对应0 ~ 9 - 计算符:
加、减对应+、-
公式中仅有这两种元素,其中对于数字的处理比较简单,只需要通过switch-case将中文名翻译成阿拉伯数字即可。
计算符怎么处理呢?计算符左右两边可能是单个数字,也可能是另一个计算公式。但无论是数字还是公式,两者都有一个共同点,那就是他们都会返回一个整数:数字返回其本身,公式返回其计算结果。
所以我们可以根据这个共同点提取出一个返回整数的接口,数字和计算符都作为该接口的实现类。在计算时,使用栈结构存储数据,将数字和计算符统一作为此接口的实现类压入栈中计算。
数字和计算符公共的接口:
interface Expression {
int intercept();
}上文已经说到,数字和计算符都属于表达式的一部分,他们的共同点是都会返回一个整数。从表达式计算出整数的过程,我们称之为解释(intercept)。
对数字类的解释实现起来相对比较简单:
public class Number implements Expression {
int number;
public Number(char word) {
switch (word) {
case '零':
number = 0;
break;
case '一':
number = 1;
break;
case '二':
number = 2;
break;
case '三':
number = 3;
break;
case '四':
number = 4;
break;
case '五':
number = 5;
break;
case '六':
number = 6;
break;
case '七':
number = 7;
break;
case '八':
number = 8;
break;
case '九':
number = 9;
break;
default:
break;
}
}
@Override
public int intercept() {
return number;
}
}在 Number 类的构造函数中,先将传入的字符转换为对应的数字。在解释时将转换后的数字返回即可。
无论是加法还是减法,他们都是对左右两个表达式进行操作,所以我们可以将计算符提取出共同的抽象父类:
abstract class Operator implements Expression {
Expression left;
Expression right;
Operator(Expression left, Expression right) {
this.left = left;
this.right = right;
}
}在此抽象父类中,我们存入了两个变量,表达计算符左右两边的表达式。
加法类实现如下:
class Add extends Operator {
Add(Expression left, Expression right) {
super(left, right);
}
@Override
public int intercept() {
return left.intercept() + right.intercept();
}
}减法类:
class Sub extends Operator {
Sub(Expression left, Expression right) {
super(left, right);
}
@Override
public int intercept() {
return left.intercept() - right.intercept();
}
}加法类和减法类都继承自 Operator 类,在对他们进行解释时,将左右两边表达式解释出的值相加或相减即可。
数字类和计算符内都定义好了,这时我们只需要再编写一个计算类将他们综合起来,统一计算即可。
计算类:
class Calculator {
int calculate(String expression) {
Stack<Expression> stack = new Stack<>();
for (int i = 0; i < expression.length(); i++) {
char word = expression.charAt(i);
switch (word) {
case '加':
stack.push(new Add(stack.pop(), new Number(expression.charAt(++i))));
break;
case '减':
stack.push(new Sub(stack.pop(), new Number(expression.charAt(++i))));
break;
default:
stack.push(new Number(word));
break;
}
}
return stack.pop().intercept();
}
}在计算类中,我们使用栈结构保存每一步操作。遍历 expression 公式:
- 遇到数字则将其压入栈中;
- 遇到计算符时,先将栈顶元素 pop 出来,再和下一个数字一起传入计算符的构造函数中,组成一个计算符公式压入栈中。
需要注意的是,入栈出栈过程并不会执行真正的计算,栈操作只是将表达式组装成一个嵌套的类对象而已。比如:
- “一加一”表达式,经过入栈出栈操作后,生成的对象是
new Add(new Number('一'), new Number('一')) - “二加五减三”表达式,经过入栈出栈操作后,生成的对象是 `new Sub(new Add(new Number(‘二’), new Number(‘五’)), new Number(‘三’))`
最后一步 stack.pop().intercept(),将栈顶的元素弹出,执行 intercept() ,这时才会执行真正的计算。计算时会将中文的数字和运算符分别解释成计算机能理解的指令。
测试类:
public class Client {
@Test
public void test() {
Calculator calculator = new Calculator();
String expression1 = "一加一";
String expression2 = "一加一加一";
String expression3 = "二加五减三";
String expression4 = "七减五加四减一";
String expression5 = "九减五加三减一";
// 输出: 一加一 等于 2
System.out.println(expression1 + " 等于 " + calculator.calculate(expression1));
// 输出: 一加一加一 等于 3
System.out.println(expression2 + " 等于 " + calculator.calculate(expression2));
// 输出: 二加五减三 等于 4
System.out.println(expression3 + " 等于 " + calculator.calculate(expression3));
// 输出: 七减五加四减一 等于 5
System.out.println(expression4 + " 等于 " + calculator.calculate(expression4));
// 输出: 九减五加三减一 等于 6
System.out.println(expression5 + " 等于 " + calculator.calculate(expression5));
}
}这就是解释器模式,我们将一句中文的公式解释给计算机,然后计算机为我们运算出了正确的结果。
分析本例中公式的组成,我们可以发现几条显而易见的性质:
- 数字类不可被拆分,属于计算中的最小单元;
- 加法类、减法类可以被拆分成两个数字(或两个公式)加一个计算符,他们不是计算的最小单元。
在解释器模式中,我们将不可拆分的最小单元称之为终结表达式,可以被拆分的表达式称之为非终结表达式。
解释器模式具有一定的拓展性,当需要添加其他计算符时,我们可以通过添加 Operator 的子类来完成。但添加后需要按照运算优先级修改计算规则。可见一个完整的解释器模式是非常复杂的,实际开发中几乎没有需要自定义解释器的情况。
解释器模式有一个常见的应用,在我们平时匹配字符串时,用到的正则表达式就是一个解释器。正则表达式中,表示一个字符的表达式属于终结表达式,除终结表达式外的所有表达式都属于非终结表达式。
迭代器模式
设想一个场景:我们有一个类中存在一个列表。这个列表需要提供给外部类访问,但我们不希望外部类修改其中的数据。
public class MyList {
private List<String> data = Arrays.asList("a", "b", "c");
}通常来说,将成员变量提供给外部类访问有两种方式:
- 将此列表设置为 public 变量;
- 添加 getData() 方法,返回此列表。
但这两种方式都有一个致命的缺点,它们无法保证外部类不修改其中的数据。外部类拿到 data 对象后,可以随意修改列表内部的元素,这会造成极大的安全隐患。
那么有什么更好的方式吗?使得外部类只能读取此列表中的数据,无法修改其中的任何数据,保证其安全性。
分析可知,我们可以通过提供两个方法实现此效果:
- 提供一个
String next()方法,使得外部类可以按照次序,一条一条的读取数据; - 提供一个
boolean hasNext()方法,告知外部类是否还有下一条数据。
代码实现如下:
public class MyList {
private List<String> data = Arrays.asList("a", "b", "c");
private int index = 0;
public String next() {
// 返回数据后,将 index 加 1,使得下次访问时返回下一条数据
return data.get(index++);
}
public boolean hasNext() {
return index < data.size();
}
}客户端就可以使用一个 while 循环来访问此列表了:
public class Client {
@Test
public void test() {
MyList list = new MyList();
// 输出:abc
while (list.hasNext()) {
System.out.print(list.next());
}
}
}由于没有给外部类暴露 data 成员变量,所以我们可以保证数据是安全的。
但这样的实现还有一个问题:当遍历完成后,hasNext() 方法就会一直返回 false,无法再一次遍历了,所以我们必须在一个合适的地方把 index 重置成 0。
在哪里重置比较合适呢?实际上,使用 next() 方法和 hasNext() 方法来遍历列表是一个完全通用的方法,我们可以为其创建一个接口,取名为 Iterator,Iterator 的意思是迭代器,迭代的意思是重复反馈,这里是指我们依次遍历列表中的元素。
public interface Iterator {
boolean hasNext();
String next();
}然后在 MyList 类中,每次遍历时生成一个迭代器,将 index 变量放到迭代器中。由于每个迭代器都是新生成的,所以每次遍历时的 index 自然也就被重置成 0 了。代码如下:
public class MyList {
private List<String> data = Arrays.asList("a", "b", "c");
// 每次生成一个新的迭代器,用于遍历列表
public Iterator iterator() {
return new Itr();
}
private class Itr implements Iterator {
private int index = 0;
@Override
public boolean hasNext() {
return index < data.size();
}
@Override
public String next() {
return data.get(index++);
}
}
}客户端访问此列表的代码修改如下:
public class Client {
@Test
public void test() {
MyList list = new MyList();
// 获取迭代器,用于遍历列表
Iterator iterator = list.iterator();
// 输出:abc
while (iterator.hasNext()) {
System.out.print(iterator.next());
}
}
}这就是迭代器模式,《设计模式》一书中将其定义如下:
迭代器模式(Iterator Pattern):提供一种方法访问一个容器对象中各个元素,而又不需暴露该对象的内部细节。
迭代器模式的核心就在于定义出 next() 方法和 hasNext() 方法,让外部类使用这两个方法来遍历列表,以达到隐藏列表内部细节的目的。
事实上,Java 已经为我们内置了 Iterator 接口,源码中使用了泛型使得此接口更加的通用:
public interface Iterator<E> {
boolean hasNext();
E next();
}并且,本例中使用的迭代器模式是仿照 ArrayList 的源码实现的,ArrayList 源码中使用迭代器模式的部分代码如下:
public class ArrayList<E> {
...
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
protected int limit = ArrayList.this.size;
int cursor;
public boolean hasNext() {
return cursor < limit;
}
public E next() {
...
}
}
}我们平时常用的 for-each 循环,也是迭代器模式的一种应用。在 Java 中,只要实现了 Iterable 接口的类,都被视为可迭代访问的。Iterable 中的核心方法只有一个,也就是刚才我们在 MyList 类中实现过的用于获取迭代器的 iterator() 方法:
public interface Iterable<T> {
Iterator<T> iterator();
}只要我们将 MyList 类修改为继承此接口,便可以使用 for-each 来迭代访问其中的数据了:
public class MyList implements Iterable<String> {
private List<String> data = Arrays.asList("a", "b", "c");
@NonNull
@Override
public Iterator<String> iterator() {
// 每次生成一个新的迭代器,用于遍历列表
return new Itr();
}
private class Itr implements Iterator<String> {
private int index = 0;
@Override
public boolean hasNext() {
return index < data.size();
}
@Override
public String next() {
return data.get(index++);
}
}
}客户端使用 for-each 访问:
public class Client {
@Test
public void test() {
MyList list = new MyList();
// 输出:abc
for (String item : list) {
System.out.print(item);
}
}
}这就是迭代器模式。基本上每种语言都会在源码层面为所有列表提供迭代器,我们只需要直接拿来用即可,这是一个比较简单又很常用的设计模式。
中介者模式
顾名思义,中介这个名字对我们来说实在太熟悉了。平时走在上班路上就会经常见到各种房产中介。他们的工作就是使得买家与卖家不需要直接打交道,只需要分别与中介打交道,就可以完成交易,用计算机术语来说就是减少了耦合度。
当类与类之间的关系呈现网状时,引入一个中介者,可以使类与类之间的关系变成星形。将每个类与多个类的耦合关系简化为每个类与中介者的耦合关系。
举个例子,在我们打麻将时,每两个人之间都可能存在输赢关系。如果每笔交易都由输家直接发给赢家,就会出现一种网状耦合关系。

我们用程序来模拟一下这个过程。
玩家类:
class Player {
// 初始资金 100 元
public int money = 100;
public void win(Player player, int money) {
// 输钱的人扣减相应的钱
player.money -= money;
// 自己的余额增加
this.money += money;
}
}此类中有一个 money 变量,表示自己的余额。当自己赢了某位玩家的钱时,调用 win 方法修改输钱的人和自己的余额。
需要注意的是,我们不需要输钱的方法,因为在 win 方法中,已经将输钱的人对应余额扣除了。
客户端代码:
public class Client {
@Test
public void test() {
Player player1 = new Player();
Player player2 = new Player();
Player player3 = new Player();
Player player4 = new Player();
// player1 赢了 player3 5 元
player1.win(player3, 5);
// player2 赢了 player1 10 元
player2.win(player1, 10);
// player2 赢了 player4 10 元
player2.win(player4, 10);
// player4 赢了 player3 7 元
player4.win(player3, 7);
// 输出:四人剩余的钱:105,120,88,97
System.out.println("四人剩余的钱:" + player1.money + "," + player2.money + "," + player3.money + "," + player4.money);
}
}在客户端中,每两位玩家需要进行交易时,都会增加程序耦合度,相当于每位玩家都需要和其他所有玩家打交道,这是一种不好的做法。
此时,我们可以引入一个中介类——微信群,只要输家将自己输的钱发到微信群里,赢家从微信群中领取对应金额即可。网状的耦合结构就变成了星形结构:
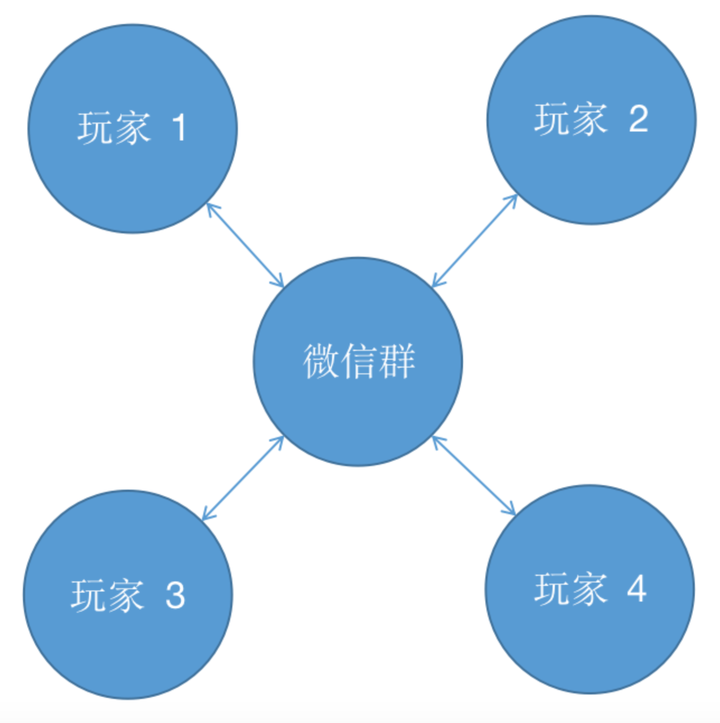
此时,微信群就充当了一个中介者的角色,由它来负责与所有人进行交易,每个玩家只需要与微信群打交道即可。
微信群类:
class Group {
public int money;
}此类中只有一个 money 变量表示群内的余额。
玩家类修改如下:
class Player {
public int money = 100;
public Group group;
public Player(Group group) {
this.group = group;
}
public void change(int money) {
// 输了钱将钱发到群里 或 在群里领取自己赢的钱
group.money -= money;
// 自己的余额改变
this.money += money;
}
}玩家类中新增了一个构造方法,在构造方法中将中介者传进来。每当自己有输赢时,只需要将钱发到群里或者在群里领取自己赢的钱,然后修改自己的余额即可。
客户端代码对应修改如下:
public class Client {
@Test
public void test(){
Group group = new Group();
Player player1 = new Player(group);
Player player2 = new Player(group);
Player player3 = new Player(group);
Player player4 = new Player(group);
// player1 赢了 5 元
player1.change(5);
// player2 赢了 20 元
player2.change(20);
// player3 输了 12 元
player3.change(-12);
// player4 输了 3 元
player4.change(-3);
// 输出:四人剩余的钱:105,120,88,97
System.out.println("四人剩余的钱:" + player1.money + "," + player2.money + "," + player3.money + "," + player4.money);
}
}可以看到,通过引入中介者,客户端的代码变得更加清晰了。大家不需要再互相打交道,所有交易通过中介者完成即可。
总而言之,中介者模式就是用于将类与类之间的 多对多关系 简化成 多对一、一对多关系 的设计模式,它的定义如下:
中介者模式(Mediator Pattern):定义一个中介对象来封装一系列对象之间的交互,使原有对象之间的耦合松散,且可以独立地改变它们之间的交互。
中介者模式的缺点也很明显:由于它将所有的职责都移到了中介者类中,也就是说中介类需要处理所有类之间的协调工作,这可能会使中介者演变成一个超级类。所以使用中介者模式时需要权衡利弊。
备忘录模式
备忘录模式最常见的实现莫过于游戏中的存档、读档功能了,通过存档、读档,使得我们可以随时恢复到之前的状态。
当我们在玩游戏时,打大 Boss 之前,通常会将自己的游戏进度存档保存,以防打不过 Boss 的话,还能重新读档恢复状态。
玩家类:
class Player {
// 生命值
private int life = 100;
// 魔法值
private int magic = 100;
public void fightBoss() {
life -= 100;
magic -= 100;
if (life <= 0) {
System.out.println("壮烈牺牲");
}
}
public int getLife() {
return life;
}
public void setLife(int life) {
this.life = life;
}
public int getMagic() {
return magic;
}
public void setMagic(int magic) {
this.magic = magic;
}
}我们为玩家定义了两个属性:生命值和魔法值。其中有一个 fightBoss() 方法,每次打 Boss 都会扣减 100 点体力。如果生命值小于等于 0,则提示用户已“壮烈牺牲”。
客户端实现如下:
public class Client {
@Test
public void test() {
Player player = new Player();
// 存档
int savedLife = player.getLife();
int savedMagic = player.getMagic();
// 打 Boss,打不过,壮烈牺牲
player.fightBoss();
// 读档,恢复到打 Boss 之前的状态
player.setLife(savedLife);
player.setMagic(savedMagic);
}
}客户端中,我们在 fightBoss() 之前,先去存档,把自己当前的生命值和魔法值保存起来。打完 Boss 发现自己牺牲之后,再回去读档,将自己恢复到打 Boss 之前的状态。
这就是备忘录模式……吗?不完全是,事情并没有这么简单。
还记得我们在原型模式中,买的那杯和周杰伦一模一样的奶茶吗?开始时,为了克隆一杯奶茶,我们将奶茶的各个属性分别赋值成和周杰伦买的那杯奶茶一样。但这样存在一个弊端:我们不可能为一千个粉丝写一千份挨个赋值操作。所以最终我们在奶茶类内部实现了 Cloneable 接口,定义了 clone() 方法,来实现一行代码拷贝所有属性。
备忘录模式也应该采取类似的做法。我们不应该采用将单个属性挨个存取的方式来进行读档、存档。更好的做法是将存档、读档交给需要存档的类内部去实现。
新建备忘录类:
class Memento {
int life;
int magic;
Memento(int life, int magic) {
this.life = life;
this.magic = magic;
}
}在此类中,管理需要存档的数据。
玩家类中,通过备忘录类实现存档、读档:
class Player {
...
// 存档
public Memento saveState() {
return new Memento(life, magic);
}
// 读档
public void restoreState(Memento memento) {
this.life = memento.life;
this.magic = memento.magic;
}
}客户端类对应修改如下:
public class Client {
@Test
public void test() {
Player player = new Player();
// 存档
Memento memento = player.saveState();
// 打 Boss,打不过,壮烈牺牲
player.fightBoss();
// 读档
player.restoreState(memento);
}
}这才是完整的备忘录模式。这个设计模式的定义如下:
备忘录模式:在不破坏封装的条件下,通过备忘录对象存储另外一个对象内部状态的快照,在将来合适的时候把这个对象还原到存储起来的状态。
备忘录模式的优点是:
- 给用户提供了一种可以恢复状态的机制,可以使用户能够比较方便的回到某个历史的状态
- 实现了信息的封装,使得用户不需要关心状态的保存细节
缺点是:
- 消耗资源,如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存。
总体而言,备忘录模式是利大于弊的,所以许多程序都为用户提供了备份方案。比如 IDE 中,用户可以将自己的设置导出成 zip,当需要恢复设置时,再将导出的 zip 文件导入即可。这个功能内部的原理就是备忘录模式。

观察者模式
观察者模式非常常见,近年来逐渐流行的响应式编程就是观察者模式的应用之一。观察者模式的思想就是一个对象发生一个事件后,逐一通知监听着这个对象的监听者,监听者可以对这个事件马上做出响应。生活中有很多观察者模式的例子,比如我们平时的开关灯。当我们打开灯的开关时,灯马上亮了;当我们关闭灯的开关时,灯马上熄了。这个过程中,灯就对我们控制开关的事件做出了响应,这就是一个最简单的一对一观察者模式。当力扣公众号发表一篇文章,所有关注了公众号的读者立即收到了文章,这个过程中所有关注了公众号的微信客户端就对公众号发表文章的事件做出了响应,这就是一个典型的一对多观察者模式。再举个例子,比如警察一直观察着张三的一举一动,只要张三有什么违法行为,警察马上行动,抓捕张三。这个过程中:
- 警察称之为观察者(Observer)
- 张三称之为被观察者(Observable,可观察的)
- 警察观察张三的这个行为称之为订阅(subscribe),或者注册(register)
- 张三违法后,警察抓捕张三的行动称之为响应(update)
众所周知,张三坏事做尽,是一个老法外狂徒了,所以不止一个警察会盯着张三,也就是说一个被观察者可以有多个观察者。当被观察者有事件发生时,所有观察者都能收到通知并响应。观察者模式主要处理的是一种一对多的依赖关系。它的定义如下:
观察者模式(Observer Pattern):定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
我们使用程序来模拟一下这个过程。
观察者的接口:
public interface Observer {
void update(String event);
}接口中只有一个 update 方法,用于对被观察者发出的事件做出响应。
被观察者的父类:
public class Observable {
private List<Observer> observers = new ArrayList<>();
public void addObserver(Observer observer) {
observers.add(observer);
}
public void removeObserver(Observer observer) {
observers.remove(observer);
}
public void notifyObservers(String event) {
for (Observer observer : observers) {
observer.update(event);
}
}
}被观察者中维护了一个观察者列表,提供了三个方法:
- addObserver:将 observer 对象添加到观察者列表中
- removeObserver:将 observer 对象从观察者列表中移除
- notifyObservers:通知所有观察者有事件发生,具体实现是调用所有观察者的 update 方法
有了这两个基类,我们就可以定义出具体的罪犯与警察类。
警察属于观察者:
public class PoliceObserver implements Observer {
@Override
public void update(String event) {
System.out.println("警察收到消息,罪犯在" + event);
}
}警察实现了观察者接口,当警察收到事件后,做出响应,这里的响应就是简单的打印了一条日志。
罪犯属于被观察者:
public class CriminalObservable extends Observable {
public void crime(String event) {
System.out.println("罪犯正在" + event);
notifyObservers(event);
}
}罪犯继承自被观察者类,当罪犯有犯罪行为时,所有的观察者都会收到通知。
客户端测试:
public class Client {
@Test
public void test() {
CriminalObservable zhangSan = new CriminalObservable();
PoliceObserver police1 = new PoliceObserver();
PoliceObserver police2 = new PoliceObserver();
PoliceObserver police3 = new PoliceObserver();
zhangSan.addObserver(police1);
zhangSan.addObserver(police2);
zhangSan.addObserver(police3);
zhangSan.crime("放狗咬人");
}
}在客户端中,我们 new 了一个张三,为其添加了三个观察者:police1,police2,police3。
运行程序,输出如下:
罪犯正在放狗咬人
警察收到消息,罪犯在放狗咬人
警察收到消息,罪犯在放狗咬人
警察收到消息,罪犯在放狗咬人可以看到,所有的观察者都被通知到了。当某个观察者不需要继续观察时,调用 removeObserver 即可。
这就是观察者模式,它并不复杂,由于生活中一对多的关系非常常见,所以观察者模式应用广泛。
Java源码中的观察者模式
实际上,Java 已经为我们提供了的 Observable 类和 Observer 类,我们在用到观察者模式时,无需自己创建这两个基类,我们来看一下 Java 中提供的源码:
java.util.Observer 类:
public interface Observer {
void update(Observable o, Object arg);
}Observer 类和我们上例中的定义基本一致,都是只有一个 update 方法用于响应 Observable 的事件。区别有两点:
- update 方法将 Observable 对象也提供给了 Observer
- update 方法中的参数类型变成了 Object
这两点区别都是为了保证此 Observer 的适用范围更广。
java.util.Observable 类:
public class Observable {
private boolean changed = false;
private Vector<Observer> obs;
public Observable() {
obs = new Vector<>();
}
public synchronized void addObserver(java.util.Observer o) {
if (o == null)
throw new NullPointerException();
if (!obs.contains(o)) {
obs.addElement(o);
}
}
public synchronized void deleteObserver(java.util.Observer o) {
obs.removeElement(o);
}
public void notifyObservers() {
notifyObservers(null);
}
public void notifyObservers(Object arg) {
Object[] arrLocal;
synchronized (this) {
if (!hasChanged())
return;
arrLocal = obs.toArray();
clearChanged();
}
for (int i = arrLocal.length - 1; i >= 0; i--)
((Observer) arrLocal[i]).update(this, arg);
}
public synchronized void deleteObservers() {
obs.removeAllElements();
}
protected synchronized void setChanged() {
changed = true;
}
protected synchronized void clearChanged() {
changed = false;
}
public synchronized boolean hasChanged() {
return changed;
}
public synchronized int countObservers() {
return obs.size();
}
}Observable 类和我们上例中的定义也是类似的,区别在于:
- 用于保存观察者列表的容器不是 ArrayList,而是 Vector
- 添加了一个 changed 字段,以及 setChanged 和 clearChanged 方法。分析可知,当 changed 字段为 true 时,才会通知所有观察者,否则不通知观察者。所以当我们使用此类时,想要触发 notifyObservers 方法,必须先调用 setChanged 方法。这个字段相当于在被观察者和观察者之间添加了一个可控制的阀门。
- 提供了 countObservers 方法,用于计算观察者数量
- 添加了一些 synchronized 关键字保证线程安全
这些区别仍然是为了让 Observable 的适用范围更广,核心思想与本文介绍的都是一致的。
上例替换为使用JDK提供的Observer接口和Observable父类
class PoliceObserver implements Observer{
@Override
public void update(Observable o, Object arg) { // 观察者
System.out.println("警察收到消息,罪犯在" + (String)arg);
}
}
public class CriminalObservable extends Observable { //被观察者
public void crime(String event) {
System.out.println("罪犯正在" + event);
setChanged();
notifyObservers(event);
}
public static void main(String[] args) {
CriminalObservable zhangSan = new CriminalObservable();
PoliceObserver police1 = new PoliceObserver();
PoliceObserver police2 = new PoliceObserver();
PoliceObserver police3 = new PoliceObserver();
zhangSan.addObserver(police1);
zhangSan.addObserver(police2);
zhangSan.addObserver(police3);
zhangSan.crime("放狗咬人");
//罪犯正在放狗咬人
//警察收到消息,罪犯在放狗咬人
//警察收到消息,罪犯在放狗咬人
//警察收到消息,罪犯在放狗咬人
}
}状态模式
状态模式(State Pattern):当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类。
通俗地说,状态模式就是一个关于多态的设计模式。
如果一个对象有多种状态,并且每种状态下的行为不同,一般的做法是在这个对象的各个行为中添加 if-else 或者 switch-case 语句。但更好的做法是为每种状态创建一个状态对象,使用状态对象替换掉这些条件判断语句,使得状态控制更加灵活,扩展性也更好。
举个例子,力扣的用户有两种状态:普通用户和 PLUS 会员。PLUS 会员有非常多的专享功能,其中“模拟面试”功能非常有特色,我们便以此为例。
- 当普通用户点击模拟面试功能时,提示用户:模拟面试是 Plus 会员专享功能;
- 当 PLUS 会员点击模拟面试功能时,开始一场模拟面试。
先来看看不使用状态模式的写法,看出它的缺点后,我们再用状态模式来重构代码。
首先定义一个用户状态枚举类:
public enum State {
NORMAL, PLUS
}NORMAL 代表普通用户状态,PLUS 代表 PLUS 会员状态。
用户的功能接口:
public interface IUser {
void mockInterview();
}本例中我们只定义了一个模拟面试的方法,实际开发中这里可能会有许许多多的方法。
用户状态切换接口:
public interface ISwitchState {
void purchasePlus();
void expire();
}此接口中定义了两个方法:purchasePlus 方法表示购买 Plus 会员,用户状态变为 PLUS 会员状态,expire 方法表示会员过期,用户状态变为普通用户状态。
力扣用户类:
public class User implements IUser, ISwitchState {
private State state = State.NORMAL;
@Override
public void mockInterview() {
if (state == State.PLUS) {
System.out.println("开始模拟面试");
} else {
System.out.println("模拟面试是 Plus 会员专享功能");
}
}
@Override
public void purchasePlus() {
state = State.PLUS;
}
@Override
public void expire() {
state = State.NORMAL;
}
}用户类实现了 IUser 接口,IUser 接口中的每个功能都需要判断用户是否为 Plus 会员,也就是说每个方法中都有 if (state == State.PLUS) {} else {} 语句,如果状态不止两种,还需要用上 switch-case 语句来判断状态,这就是不使用状态模式的弊端:
- 判断用户状态会产生大量的分支判断语句,导致代码冗长;
- 当状态有增加或减少时,需要改动多个地方,违反开闭原则。
在《代码整洁之道》、《重构》两本书中都提到:应使用多态取代条件表达式。接下来我们就利用多态特性重构这份代码。为每个状态新建一个状态类,普通用户:
class Normal implements IUser {
@Override
public void mockInterview() {
System.out.println("模拟面试是 Plus 会员专享功能");
}
}PLUS 会员:
class Plus implements IUser {
@Override
public void mockInterview() {
System.out.println("开始模拟面试");
}
}每个状态类都实现了 IUser 接口,在接口方法中实现自己特定的行为。
用户类:
class User implements IUser, ISwitchState {
IUser state = new Normal();
@Override
public void mockInterview() {
state.mockInterview();
}
@Override
public void purchasePlus() {
state = new Plus();
}
@Override
public void expire() {
state = new Normal();
}
}可以看到,丑陋的状态判断语句消失了,无论 IUser 接口中有多少方法,User 类都只需要调用状态类的对应方法即可。
客户端测试:
public class Client {
@Test
public void test() {
// 用户初始状态为普通用户
User user = new User();
// 输出:模拟面试是 Plus 会员专享功能
user.mockInterview();
// 用户购买 Plus 会员,状态改变
user.purchasePlus();
// 输出:开始模拟面试
user.mockInterview();
// Plus 会员过期,变成普通用户,状态改变
user.expire();
// 输出:模拟面试是 Plus 会员专享功能
user.mockInterview();
}
}可以看到,用户状态改变后,行为也随着改变了,这就是状态模式定义的由来,它的优点是:将与特定状态相关的行为封装到一个状态对象中,使用多态代替 if-else 或者 switch-case 状态判断。缺点是必然导致类增加,这也是使用多态不可避免的缺点。
策略模式
策略模式用一个成语就可以概括 —— 殊途同归。当我们做同一件事有多种方法时,就可以将每种方法封装起来,在不同的场景选择不同的策略,调用不同的方法。
策略模式(Strategy Pattern):定义了一系列算法,并将每一个算法封装起来,而且使它们还可以相互替换。策略模式让算法独立于使用它的客户而独立变化。
我们以排序算法为例。排序算法有许多种,如冒泡排序、选择排序、插入排序,算法不同但目的相同,我们可以将其定义为不同的策略,让用户自由选择采用哪种策略完成排序。
首先定义排序算法接口:
interface ISort {
void sort(int[] arr);
}接口中只有一个 sort 方法,传入一个整型数组进行排序,所有的排序算法都实现此接口。
冒泡排序:
class BubbleSort implements ISort{
@Override
public void sort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
// 如果左边的数大于右边的数,则交换,保证右边的数字最大
arr[j + 1] = arr[j + 1] + arr[j];
arr[j] = arr[j + 1] - arr[j];
arr[j + 1] = arr[j + 1] - arr[j];
}
}
}
}
}选择排序:
class SelectionSort implements ISort {
@Override
public void sort(int[] arr) {
int minIndex;
for (int i = 0; i < arr.length - 1; i++) {
minIndex = i;
for (int j = i + 1; j < arr.length; j++) {
if (arr[minIndex] > arr[j]) {
// 记录最小值的下标
minIndex = j;
}
}
// 将最小元素交换至首位
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
}
}插入排序:
class InsertSort implements ISort {
@Override
public void sort(int[] arr) {
// 从第二个数开始,往前插入数字
for (int i = 1; i < arr.length; i++) {
int currentNumber = arr[i];
int j = i - 1;
// 寻找插入位置的过程中,不断地将比 currentNumber 大的数字向后挪
while (j >= 0 && currentNumber < arr[j]) {
arr[j + 1] = arr[j];
j--;
}
// 两种情况会跳出循环:1. 遇到一个小于或等于 currentNumber 的数字,跳出循环,currentNumber 就坐到它后面。
// 2. 已经走到数列头部,仍然没有遇到小于或等于 currentNumber 的数字,也会跳出循环,此时 j 等于 -1,currentNumber 就坐到数列头部。
arr[j + 1] = currentNumber;
}
}
}这三种都是基本的排序算法,就不再详细介绍了。接下来我们需要创建一个环境类,将每种算法都作为一种策略封装起来,客户端将通过此环境类选择不同的算法完成排序。
class Sort implements ISort {
private ISort sort;
Sort(ISort sort) {
this.sort = sort;
}
@Override
public void sort(int[] arr) {
sort.sort(arr);
}
// 客户端通过此方法设置不同的策略
public void setSort(ISort sort) {
this.sort = sort;
}
}在此类中,我们保存了一个 ISort 接口的实现对象,在构造方法中,将其初始值传递进来,排序时调用此对象的 sort 方法即可完成排序。
我们也可以为 ISort 对象设定一个默认值,客户端如果没有特殊需求,直接使用默认的排序策略即可。
setSort 方法就是用来选择不同的排序策略的,客户端调用如下:
public class Client {
@Test
public void test() {
int[] arr = new int[]{6, 1, 2, 3, 5, 4};
Sort sort = new Sort(new BubbleSort());
// 这里可以选择不同的策略完成排序
// sort.setSort(new InsertSort());
// sort.setSort(new SelectionSort());
sort.sort(arr);
// 输出 [1, 2, 3, 4, 5, 6]
System.out.println(Arrays.toString(arr));
}
}这就是基本的策略模式,通过策略模式我们可以为同一个需求选择不同的算法,以应付不同的场景。比如我们知道冒泡排序和插入排序是稳定的,而选择排序是不稳定的,当我们需要保证排序的稳定性就可以采用冒泡排序和插入排序,不需要保证排序的稳定性时可以采用选择排序。
策略模式还可以应用在图片缓存中,当我们开发一个图片缓存框架时,可以通过提供不同的策略类,让用户根据需要选择缓存解码后的图片、缓存未经解码的数据或者不缓存任何内容。在一些开源的图片加载框架中,就采用了这种设计。
策略模式扩展性和灵活性都相当不错。当有新的策略时,只需要增加一个策略类;要修改某个策略时,只需要更改具体的策略类,其他地方的代码都无需做任何调整。
但现在这样的策略模式还有一个弊端,如本系列第一篇文章中的工厂模式所言:每 new 一个对象,相当于调用者多知道了一个类,增加了类与类之间的联系,不利于程序的松耦合。
所以使用策略模式时,更好的做法是与工厂模式结合,将不同的策略对象封装到工厂类中,用户只需要传递不同的策略类型,然后从工厂中拿到对应的策略对象即可。接下来我们就来一起实现这种工厂模式与策略模式结合的混合模式。
创建排序策略枚举类:
enum SortStrategy {
BUBBLE_SORT,
SELECTION_SORT,
INSERT_SORT
}在 Sort 类中使用简单工厂模式:
class Sort implements ISort {
private ISort sort;
Sort(SortStrategy strategy) {
setStrategy(strategy);
}
@Override
public void sort(int[] arr) {
sort.sort(arr);
}
// 客户端通过此方法设置不同的策略
public void setStrategy(SortStrategy strategy) {
switch (strategy) {
case BUBBLE_SORT:
sort = new BubbleSort();
break;
case SELECTION_SORT:
sort = new SelectionSort();
break;
case INSERT_SORT:
sort = new InsertSort();
break;
default:
throw new IllegalArgumentException("There's no such strategy yet.");
}
}
}利用简单工厂模式,我们将创建策略类的职责移到了 Sort 类中。如此一来,客户端只需要和 Sort 类打交道,通过 SortStrategy 选择不同的排序策略即可。
客户端:
public class Client {
@Test
public void test() {
int[] arr = new int[]{6, 1, 2, 3, 5, 4};
Sort sort = new Sort(SortStrategy.BUBBLE_SORT);
// 可以通过选择不同的策略完成排序
// sort.setStrategy(SortStrategy.SELECTION_SORT);
// sort.setStrategy(SortStrategy.INSERT_SORT);
sort.sort(arr);
// 输出 [1, 2, 3, 4, 5, 6]
System.out.println(Arrays.toString(arr));
}
}通过简单工厂模式与策略模式的结合,我们最大化地减轻了客户端的压力。这是我们第一次用到混合模式,但实际开发中会遇到非常多的混合模式,学习设计模式的过程只能帮助我们各个击破,真正融会贯通还需要在实际开发中多加操练。
需要注意的是,策略模式与状态模式非常类似,甚至他们的 UML 类图都是一模一样的。两者都是采用一个变量来控制程序的行为。策略模式通过不同的策略执行不同的行为,状态模式通过不同的状态值执行不同的行为。两者的代码很类似,他们的区别主要在于程序的目的不同。
- 使用策略模式时,程序只需选择一种策略就可以完成某件事。也就是说每个策略类都是完整的,都能独立完成这件事情,如上文所言,强调的是
殊途同归。 - 使用状态模式时,程序需要在不同的状态下不断切换才能完成某件事,每个状态类只能完成这件事的一部分,需要所有的状态类组合起来才能完整的完成这件事,强调的是
随势而动。
模板方法模式
模板方法模式(Template Method Pattern):定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
通俗地说,模板方法模式就是一个关于继承的设计模式。
每一个被继承的父类都可以认为是一个模板,它的某些步骤是稳定的,某些步骤被延迟到子类中实现。
这和我们平时生活中使用的模板也是一样的。比如我们请假时,通常会给我们一份请假条模板,内容是已经写好的,只需要填写自己的姓名和日期即可。
本人 ___ 因 ___ 需请假 ___ 天,望批准!这个模板用代码表示如下:
abstract class LeaveRequest {
void request() {
System.out.print("本人");
System.out.print(name());
System.out.print("因");
System.out.print(reason());
System.out.print("需请假");
System.out.print(duration());
System.out.print("天,望批准");
}
abstract String name();
abstract String reason();
abstract String duration();
}在这份模板中,所有的其他步骤(固定字符串)都是稳定的,只有姓名、请假原因、请假时长是抽象的,需要延迟到子类去实现。
继承此模板,实现具体步骤的子类:
class MyLeaveRequest extends LeaveRequest {
@Override
String name() {
return "小明";
}
@Override
String reason() {
return "需要休息";
}
@Override
String duration() {
return "0.5";
}
}测试:
// 输出:本人小明因需要休息需请假0.5天,望批准
new MyLeaveRequest().request();在使用模板方法模式时,我们可以为不同的模板方法设置不同的控制权限:
- 如果不希望子类覆写模板中的某个方法,使用 final 修饰此方法;
- 如果要求子类必须覆写模板中的某个方法,使用 abstract 修饰此方法;
- 如果没有特殊要求,可使用 protected 或 public 修饰此方法,子类可根据实际情况考虑是否覆写。
访问者模式
许多设计模式的书中都说访问者模式是最复杂的设计模式,实际上只要我们对它抽丝剥茧,就会发现访问者模式的核心思想并不复杂。
以我们去吃自助餐为例,每个人喜欢的食物是不一样的,比如 Aurora 喜欢吃龙虾和西瓜,Kevin 喜欢吃牛排和香蕉,餐厅不可能单独为某一位顾客专门准备食物。所以餐厅的做法是将所有的食物都准备好,顾客按照需求自由取用。此时,顾客和餐厅之间就形成了一种访问者与被访问者的关系。
准备好各种食物的餐厅:
class Restaurant {
private String lobster = "lobster";
private String watermelon = "watermelon";
private String steak = "steak";
private String banana = "banana";
}在餐厅类中,我们提供了四种食物:龙虾、西瓜、牛排、香蕉。
为顾客提供的接口:
public interface IVisitor {
void chooseLobster(String lobster);
void chooseWatermelon(String watermelon);
void chooseSteak(String steak);
void chooseBanana(String banana);
}接口中提供了四个方法, 让顾客依次选择每种食物。
在餐厅中提供接收访问者的方法:
class Restaurant {
...
public void welcome(IVisitor visitor) {
visitor.chooseLobster(lobster);
visitor.chooseWatermelon(watermelon);
visitor.chooseSteak(steak);
visitor.chooseBanana(banana);
}
}在 welcome 方法中,我们将食物依次传递给访问者对应的访问方法。这时候,顾客如果想要访问餐厅选择自己喜欢的食物,只需要实现 IVisitor 接口即可。
比如顾客 Aurora 类:
public class Aurora implements IVisitor {
@Override
public void chooseLobster(String lobster) {
System.out.println("Aurora gets a " + lobster);
}
@Override
public void chooseWatermelon(String watermelon) {
System.out.println("Aurora gets a " + watermelon);
}
@Override
public void chooseSteak(String steak) {
System.out.println("Aurora doesn't like " + steak);
}
@Override
public void chooseBanana(String banana) {
System.out.println("Aurora doesn't like " + banana);
}
}在此类中,顾客根据自己的喜好依次选择每种食物。
客户端测试:
public class Client {
@Test
public void test() {
Restaurant restaurant = new Restaurant();
IVisitor Aurora = new Aurora();
restaurant.welcome(Aurora);
}
}运行程序,输出如下:
Aurora gets a lobster
Aurora gets a watermelon
Aurora doesn't like steak
Aurora doesn't like banana可以看到,Aurora 对每一种食物做出了自己的选择,这就是一个最简单的访问者模式,它已经体现出了访问者模式的核心思想:将数据的结构和对数据的操作分离。
访问者模式(Visitor Pattern):表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
本例中,顾客需要选择餐厅的食物,由于每个顾客对食物的选择是不一样的,如果在餐厅类中处理每位顾客的需求,必然导致餐厅类职责过多。所以我们并没有在餐厅类中处理顾客的需求,而是将所有的食物通过接口暴露出去,欢迎每位顾客来访问。顾客只要实现访问者接口就能访问到所有的食物,然后在接口方法中做出自己的选择。
相信这个例子还是非常简单直观的,看起来访问者模式也不是那么难理解。那么为什么很多书中说访问者模式是最复杂的设计模式呢?原因就在于《设计模式》一书中给访问者模式设计了一个“双重分派”的机制,而 Java 只支持单分派,用单分派语言强行模拟出双重分派才导致了访问者模式看起来比较复杂。要理解这一点,我们先来了解一下何谓单分派、何谓双重分派。
单分派与双重分派
先看一段代码:
Food 类:
public class Food {
public String name() {
return "food";
}
}Watermelon 类,继承自 Food 类:
public class Watermelon extends Food {
@Override
public String name() {
return "watermelon";
}
}在 Watermelon 类中,我们重写了name()方法。
客户端:
public class Client {
@Test
public void test() {
Food food = new Watermelon();
System.out.println(food.name());
}
}思考一下,在客户端中,我们 new 出了一个 Watermelon 对象,但他的声明类型是 Food,当我们调用此对象的 name 方法时,会输出 “food” 还是 “watermelon” 呢?
了解过 Java 多态特性的同学都知道,这里肯定是输出 “watermelon” ,因为 Java 调用重写方法时,会根据运行时的具体类型来确定调用哪个方法。
再来看一段测试代码:
public class Client {
@Test
public void test() {
Food food = new Watermelon();
eat(food);
}
public void eat(Food food) {
System.out.println("eat food");
}
public void eat(Watermelon watermelon) {
System.out.println("eat watermelon");
}
}在这段代码中,我们仍然 new 出了一个 Watermelon 对象,他的声明类型是 Food,在客户端中有eat(Food food)和eat(Watermelon watermelon)两个重载方法,这段代码会调用哪一个方法呢?
我们运行这段代码会发现输出的是:
eat food这是由于 Java 在调用重载方法时,只会根据方法签名中声明的参数类型来判断调用哪个方法,不会去判断参数运行时的具体类型是什么。
从这两个例子中,我们可以看出 Java 对重写方法和重载方法的调用方式是不同的。
- 调用重写方法时,与对象的运行时类型有关;
- 调用重载方法时,只与方法签名中声明的参数类型有关,与对象运行时的具体类型无关。
了解了重写方法和重载方法调用方式的区别之后,我们将其综合起来就能理解何谓双重分派了。
测试代码:
public class Client {
@Test
public void test() {
Food food = new Watermelon();
eat(food);
}
public void eat(Food food) {
System.out.println("eat food: " + food.name());
}
public void eat(Watermelon watermelon) {
System.out.println("eat watermelon" + watermelon.name());
}
}在这段测试代码中,仍然是 new 出了一个 Watermelon 对象,它的声明类型为 Food。运行test()函数,输出如下:
eat food: watermelon在面向对象的编程语言中,我们将方法调用称之为分派,这段测试代码运行时,经过了两次分派:
- 调用重载方法:选择调用
eat(Food food)还是eat(Watermelon watermelon)。虽然这里传入的这个参数实际类型是Watermelon,但这里会调用eat(Food food),这是由于调用哪个重载方法是在编译期就确定了的,也称之为静态分派。 - 调用重写方法:选择调用
Food的name方法还是Watermelon的name方法。这里会根据参数运行时的实际类型,调用Watermelon的name方法,称之为动态分派。
单分派、双重分派的定义如下:
方法的接收者和方法的参数统称为方法的宗量。 根据分派基于多少个宗量,可以将分派分为单分派和多分派。单分派是指根据一个宗量就可以知道应该调用哪个方法,多分派是指需要根据多个宗量才能确定调用目标。
这段定义可能不太好理解,通俗地讲,单分派和双重分派的区别就是:程序在选择重载方法和重写方法时,如果两种情况都是动态分派的,则称之为双重分派;如果其中一种情况是动态分派,另一种是静态分派,则称之为单分派。
说了这么多,这和我们的访问者模式有什么关系呢?首先我们要知道,架构的演进往往都是由复杂的业务驱动的,当程序需要更好的扩展性,更灵活的架构便诞生出来。
上例中的程序非常简单,但它无法处理某种食物有多个的情形。接下来我们就来修改一下程序,来应对每种食物有多个的场景。
自助餐程序 2.0 版
在上面的例子中,为了突出访问者模式的特点,我们将每种食物都简化为了 String 类型,实际开发中,每种食物都应该是一个单独的对象,统一继承自父类 Food:
public abstract class Food {
public abstract String name();
}继承自 Food 的四种食物:
public class Lobster extends Food {
@Override
public String name() {
return "lobster";
}
}
public class Watermelon extends Food {
@Override
public String name() {
return "watermelon";
}
}
public class Steak extends Food {
@Override
public String name() {
return "steak";
}
}
public class Banana extends Food {
@Override
public String name() {
return "banana";
}
}四个子类中分别重写了 name 方法,返回自己的食物名。
IVisitor 接口对应修改为:
public interface IVisitor {
void chooseFood(Lobster lobster);
void chooseFood(Watermelon watermelon);
void chooseFood(Steak steak);
void chooseFood(Banana banana);
}每种食物都继承自 Food,所以我们将接口中的方法名都修改为了 chooseFood。
餐厅类修改如下:
class Restaurant {
// 准备当天的食物
private List<Food> prepareFoods() {
List<Food> foods = new ArrayList<>();
// 简单模拟,每种食物添加 10 份
for (int i = 0; i < 10; i++) {
foods.add(new Lobster());
foods.add(new Watermelon());
foods.add(new Steak());
foods.add(new Banana());
}
return foods;
}
// 欢迎顾客来访
public void welcome(IVisitor visitor) {
// 获取当天的食物
List<Food> foods = prepareFoods();
// 将食物依次提供给顾客选择
for (Food food : foods) {
// 由于单分派机制,此处无法编译通过
visitor.chooseFood(food);
}
}
}餐厅类中新增了prepareFoods方法,在这个方法中,我们简单模拟了准备多个食物的过程,将每种食物添加了 10 份。在接收访问者的welcome方法中,遍历所有食物,分别提供给顾客。
看起来很美好,实际上,visitor.chooseFood(food)这一行是无法编译通过的,原因就在于上一节中提到的单分派机制。虽然每种食物都继承自 Food 类,但由于接口中没有chooseFood(Food food)这个重载方法,所以这一行会报错”Cannot resolve method chooseFood”。
试想,如果 Java 在调用重载方法时也采用动态分派,也就是根据参数的运行时类型选择对应的重载方法,这里遇到的问题就迎刃而解了,我们的访问者模式讲到这里也就可以结束了。
但由于 Java 是单分派语言,所以我们不得不想办法解决这个 bug,目的就是使用单分派的 Java 语言模拟出双分派的效果,能够根据运行时的具体类型调用对应的重载方法。
我们很容易想到一种解决方式,采用 instanceOf 判断对象的具体子类型,再将父类强制转换为具体子类型,调用对应的接口方法:
// 通过 instanceOf 判断具体子类型,再强制向下转型
if (food instanceof Lobster) visitor.chooseFood((Lobster) food);
else if (food instanceof Watermelon) visitor.chooseFood((Watermelon) food);
else if (food instanceof Steak) visitor.chooseFood((Steak) food);
else if (food instanceof Banana) visitor.chooseFood((Banana) food);
else throw new IllegalArgumentException("Unsupported type of food.");的确可行,在某些开源代码中便是这么做的,但这种强制转型的方式既冗长又不符合开闭原则,所以《设计模式》一书中给我们推荐了另一种做法。
首先在 Food 类中添加 accept(Visitor visitor) 抽象方法:
public abstract class Food {
public abstract String name();
// Food 中添加 accept 方法,接收访问者
public abstract void accept(IVisitor visitor);
}在具体子类中,实现此方法:
public class Lobster extends Food {
@Override
public String name() {
return "lobster";
}
@Override
public void accept(IVisitor visitor) {
visitor.chooseFood(this);
}
}经过这两步修改,餐厅类就可以将接收访问者的方法修改如下:
class Restaurant {
// 准备当天的食物
private List<Food> prepareFoods() {
List<Food> foods = new ArrayList<>();
// 简单模拟,每种食物添加 10 份
for (int i = 0; i < 10; i++) {
foods.add(new Lobster());
foods.add(new Watermelon());
foods.add(new Steak());
foods.add(new Banana());
}
return foods;
}
// 欢迎顾客来访
public void welcome(IVisitor visitor) {
// 获取当天的食物
List<Food> foods = prepareFoods();
// 将食物依次提供给顾客选择
for (Food food : foods) {
// 由于重写方法是动态分派的,所以这里会调用具体子类的 accept 方法,
food.accept(visitor);
}
}
}经过这三步修改,我们将访问者来访的代码由:
visitor.chooseFood(food);改成了
food.accept(visitor);这样我们就将重载方法模拟成了动态分派。这里的实现非常巧妙,由于 Java 调用重写方法时是动态分派的,所以food.accept(visitor)会调用具体子类的 accept 方法,在具体子类的 accept 方法中,调用visitor.chooseFood(this),由于这个 accept 方法是属于具体子类的,所以这里的 this 一定是指具体的子类型,不会产生歧义。
再深入分析一下:之前的代码中,调用visitor.chooseFood(food)这行代码时,由于重载方法不知道 Food 的具体子类型导致了编译失败,但实际上这时我们是可以拿到 Food 的具体子类型的。利用重写方法会动态分派的特性,我们在子类的重写方法中去调用这些重载的方法,使得重载方法使用起来也像是动态分派的一样。
顾客 Aurora 类:
public class Aurora implements IVisitor {
@Override
public void chooseFood(Lobster lobster) {
System.out.println("Aurora gets a " + lobster.name());
}
@Override
public void chooseFood(Watermelon watermelon) {
System.out.println("Aurora gets a " + watermelon.name());
}
@Override
public void chooseFood(Steak steak) {
System.out.println("Aurora doesn't like " + steak.name());
}
@Override
public void chooseFood(Banana banana) {
System.out.println("Aurora doesn't like " + banana.name());
}
}顾客 Kevin 类:
public class Kevin implements IVisitor {
@Override
public void chooseFood(Lobster lobster) {
System.out.println("Kevin doesn't like " + lobster.name());
}
@Override
public void chooseFood(Watermelon watermelon) {
System.out.println("Kevin doesn't like " + watermelon.name());
}
@Override
public void chooseFood(Steak steak) {
System.out.println("Kevin gets a " + steak.name());
}
@Override
public void chooseFood(Banana banana) {
System.out.println("Kevin gets a " + banana.name());
}
}客户端测试:
public class Client {
@Test
public void test() {
Restaurant restaurant = new Restaurant();
IVisitor Aurora = new Aurora();
IVisitor Kevin = new Kevin();
restaurant.welcome(Aurora);
restaurant.welcome(Kevin);
}
}运行程序,输出如下:
Aurora gets a lobster
Aurora gets a watermelon
Aurora doesn't like steak
Aurora doesn't like banana
... 输出 10 遍
Kevin doesn't like lobster
Kevin doesn't like watermelon
Kevin gets a steak
Kevin gets a banana
... 输出 10 遍这就是访问者模式,它的核心思想其实非常简单,就是第一小节中体现的将数据的结构与对数据的操作分离。之所以说它复杂,主要在于大多数语言都是单分派语言,所以不得不模拟出一个双重分派,也就是用重写方法的动态分派特性将重载方法也模拟成动态分派。
但模拟双重分派只是手段,不是目的。有的文章中说模拟双重分派是访问者模式的核心,还有的文章中说双分派语言不需要访问者模式,笔者认为这些说法都有点舍本逐末了。