


前排声明,算法总结中的刷题顺序完全依照Carl的代码随想录。
在解决了二叉树的问题后,我们正式迎来了回溯法的时代。二叉树中会多次使用递归来解决各种问题,而回溯与递归是深度绑定的,即回溯是递归的副产品,只要有递归就会有回溯。
回溯法实际上是暴力搜索,并不是很高效的算法,但是会通过剪枝来优化性能。
回溯法经常解决的问题有:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 棋盘问题:N皇后,解数独等等
在Carl的讲解中,会将回溯法抽象成树形结构,个人认为这是最直观的讲解方式,一目了然。
回溯法拥有自己固定的模板,简称为回溯三部曲:
- 回溯函数模板返回值以及参数
- 回溯函数终止条件
- 回溯搜索的遍历过程
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}组合问题
以leetcode77组合一题为例,模拟回溯过程很容易得出下图的树形结构(这里copy一下Carl的图片):
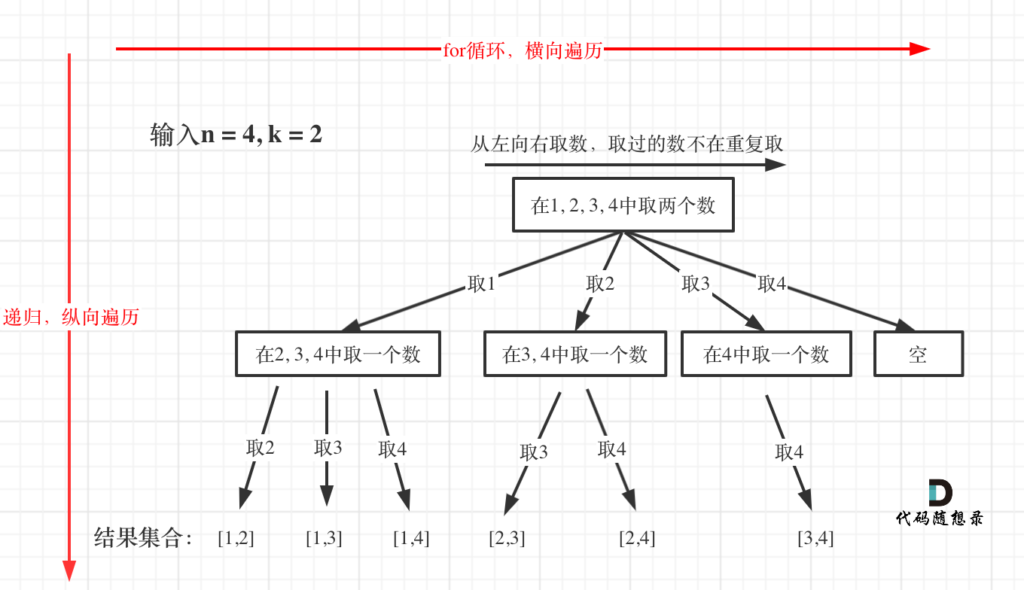
如图所示,不难发现for循环是横向遍历,递归是纵向遍历,两者正好对应了树层和树枝,而回溯法的本质就是在树层与树枝间不断找寻结果集。
不难写出代码:
class Solution {
public ArrayList<List<Integer>> res = new ArrayList<>(); // 存放结果集
public ArrayList<Integer> path = new ArrayList<>(); // 存放符合条件的组合
// startIndex是起始数
public void backTracking(int n, int k, int startIndex) {
if (k == path.size()) {
res.add(new ArrayList<>(path)); // 深拷贝,非引用
return;
}
for (int i = startIndex; i <= n; i++) {
path.add(i);
backTracking(n, k, i + 1);
path.remove(path.size() - 1);
}
}
public List<List<Integer>> combine(int n, int k) {
backTracking(n, k, 1);
return res;
}
}这里要格外注意的是,res.add(new ArrayList<>(path));这一句。如果直接传入path,实际是传入了path列表的引用,后续对path的修改都会影响path的元素,所以这里要使用Java的深拷贝来复制一个新的列表传入。
有回溯必然要有剪枝来优化性能,这道题的剪枝可以这样想:
我们要求取k个元素,如果在树形结构的遍历过程中,此时选取的元素+剩余元素+已选元素的总个数不够k个,那么没有必要再去选择这个元素和其之后的元素,所以这就是剪枝条件:
- 已经选取的元素个数: path.size()
- 还需要的元素个数:k – path.size()
- 集合n中至多可以开始的起始位置:n – (k – path.size()) + 1
修改for循环条件,增加上述剪枝条件即可:
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++)再以leetcode40组合总和II为例,这道题给出的数组 candidates 中会含有重复元素,要求解集的元素可以有重复,但要求解集不能包含重复的组合。
class Solution {
public ArrayList<List<Integer>> res = new ArrayList<>();
public ArrayList<Integer> path = new ArrayList<>();
public void backTracking(int[] candidates, int target, int sum, int startIndex) {
if (sum > target) return;
if (sum == target) {
res.add(new ArrayList<>(path));
return;
}
for (int i = startIndex; i < candidates.length && sum + candidates[i] <= target; i++) {
if (i > startIndex && candidates[i] == candidates[i - 1]) continue;
sum += candidates[i];
path.add(candidates[i]);
backTracking(candidates, target, sum, i + 1);
sum -= candidates[i];
path.remove(path.size() - 1);
}
}
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);
backTracking(candidates, target, 0, 0);
return res;
}
}这里涉及到了树层去重的概念,根据代码中的剪枝条件来看:
if (i > startIndex && candidates[i] == candidates[i - 1]) continue;这里的思想是,candidates数组中如果有相同元素,在前一个元素已经被选取的情况下,遍历到后一个元素时会直接跳过。直观的来讲,以 [1, 1, 2] 为例,在选取前一个1之后,这个1的之后纵向递归的树枝的选取情况已经包含了后一个1纵向递归的所有选取情况,自然可以跳过后一个1。
重要的是,要使用这个树层去重的剪枝条件,需要数组有序。
上面两道题,都使用了startIndex作为每次遍历的起始值,防止每次都从0开始重复选取元素,而对于组合问题,startIndex也可以不使用:
- 如果是一个集合来求组合的话,就需要startIndex(leetcode77、216)
- 如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex(leetcode17)
另外,切割问题也和组合问题非常类似,可以使用相同的思路。
子集问题
在树形结构中子集问题是要收集所有节点的结果,而组合问题是收集叶子节点的结果,例如leetcode78。
子集问题中,有些题目可以不写终止条件,因为上面已经说了,子集问题收集的是所有节点的结果。
排列问题
排列问题也是求叶子结点的结果,但是不需要startIndex,因为每一层都是从0开始搜索。
另外,排列问题通常需要used数组(和题目给出的数组等长,元素为0和1)来记录path列表中已经存放过哪些元素。也可以使用set集合来去重,但是set集合的性能通常不如使用数组,因为在运行过程中set集合要频繁的进行哈希映射。
棋盘问题
经典的棋盘问题主要有N皇后和解数独。
N皇后的思想是,我们将棋盘的搜索过程抽象为一棵树,每一层代表同一行的不同位置,而递归的过程即为下一行的不同位置。
解数独的思想是二维递归,即一个for循环遍历棋盘的行,一个for循环遍历棋盘的列,一行一列确定下来之后,递归遍历这个位置放9个数字的可能性。